Imagine o seguinte desafio: a aplicação que você vai criar precisa tomar alguma ação quando o valor total das vendas de um produto atingir um valor pré-determinado.
Como você faria isso? Agora imagine que seu sistema é baseado em Apache Kafka para comunicação entre os módulos. Pensou em usar o Kafka Stream? Pensou bem, mas com o KSQL você consegue isso também de maneira MAIS FÁCIL, e é exatamente sobre isso que vamos conversar nesse artigo.
O que é uma stream?
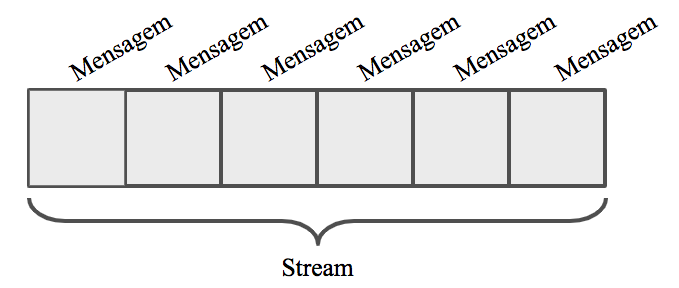
Pense no stream como uma história, ou seja, não é apenas uma mensagem. Cada mensagem ao chegar no Kafka é adicionada a um tópico, que é independente e nunca tem fim. As mensagens não têm relação uma com a outra e podem ser processadas independentemente também.
Como exemplo, imaginem os clicks em um site, pedidos de compra ou tweets. Repare como cada um gera várias mensagens, independentes, não tem um fim e podem ser processadas isoladamente. Pensar no stream é pensar em todas essas mensagens juntas, o conjunto ou o fluxo delas.
Leia também: O que é Desenvolvimento Back-end.
Processamento de streams
Nós podemos querer tomar decisões baseadas nesse fluxo, no que aconteceu e vem acontecendo, e é aí que entra o conceito de “processamento de streams“.
Podemos criar algo como: “envie um e-mail para o gerente caso o valor total das vendas passe de R$10.000”, por exemplo.
Agora o céu é o limite! Você pode usar isso para detectar fraudes e negar a transação de um cartão de crédito, por exemplo, caso o cartão de um mesmo usuário seja usado em dois lugares geográficos diferentes em um intervalo de tempo muito curto.
Como instalar o Confluent Platform
O primeiro passo é baixar e instalar o Confluent Platform para conseguirmos de forma fácil iniciar todos os serviços necessários.
Acesse aqui e faça o download para sua máquina. Para o exemplo citado nesse artigo, estou usando a versão 5.2.1 em um Mac, mas funcionará normalmente no Linux também. Se quiser pode usar a última versão também, a 5.3.0, que não fará diferença.
Se você estiver no Windows, recomendo a instalação de uma máquina virtual com algum Linux (Ubuntu ou CentOS).
A instalação é extremamente simples…
Basta descompactar e extrair em um local de sua preferência. Eu, particularmente, gosto de colocar na <HOME>/programs. Depois disso, crio um link simbólico (você já vai entender o motivo) dessa forma:

Configure a variável de ambiente PATH adicionando a pasta/bin de “confluent”.
Eu prefiro criar esse link simbólico para facilitar a atualização de versões, pois se eu baixar a versão 5.3.0 é só fazer o novo apontamento e pronto, não preciso alterar mais nada.
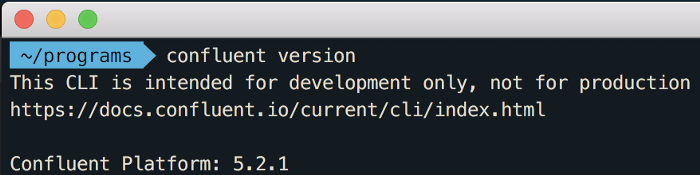
Para confirmar se a instalação ocorreu com sucesso, execute o comando abaixo:
E finalmente vamos iniciar todos os serviços necessários para trabalharmos com o KSQL:
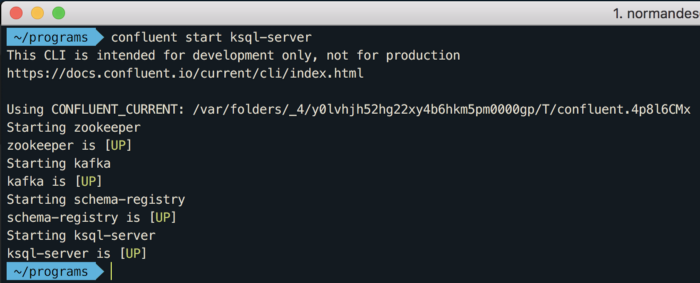
Repare que é iniciado o “zookeeper”, “kafka”, “schema-registry” e o “ksql-server”. O comando “confluent status” mostra o que está iniciado e o que está parado:
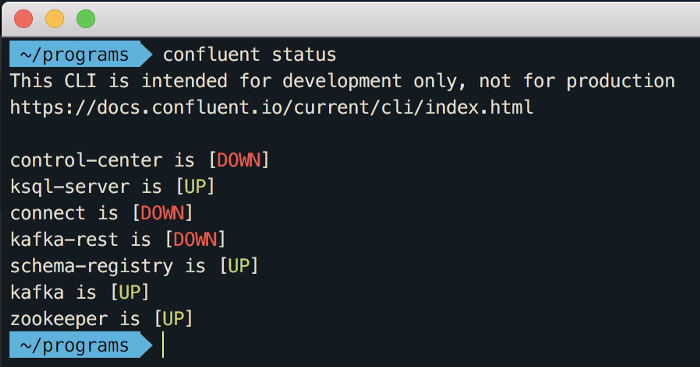
Para esse exemplo não precisamos do “control-center”, “connect” e “kafka-rest”.
KSQL CLI
O KSQL vem com um CLI para podermos começar a brincar com ele criando nossas streams baseadas nos tópicos do Apache Kafka. É bem simples acessá-lo, basta executar o comando: ksql
Você consegue listar os tópicos e streams existentes apenas usando no CLI “list topics;” ou “list streams;”, como abaixo:
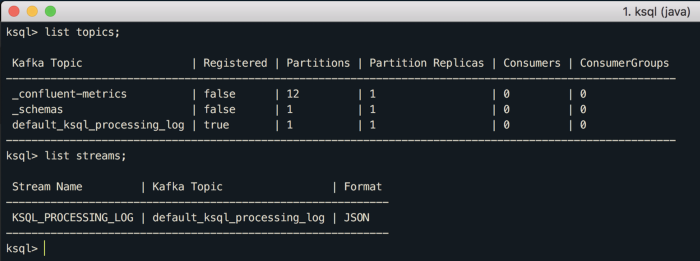
Esses tópicos e stream são os default que já nasceram no Confluent Platform.
Meu primeiro stream com KSQL
Vamos criar um stream simples, mas que já irá te ajudar a começar e dar os primeiros passos na tecnologia.
Primeiro passo:
Criar um tópico no Kafka usando o “kafka-topics”, que já está instalado através do Confluent Platform. Abra uma nova janela no terminal e rode o comando abaixo:

Volte no CLI do KSQL e execute o “list topics;” novamente:
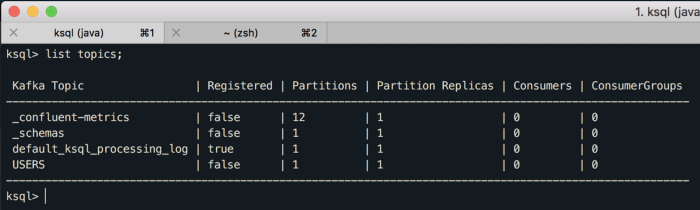
Agora podemos criar nossa primeira stream, que será baseada nesse tópico “USERS”:
create stream users_stream (name VARCHAR, statecode VARCHAR) WITH (KAFKA_TOPIC=’USERS’, VALUE_FORMAT=’DELIMITED’);
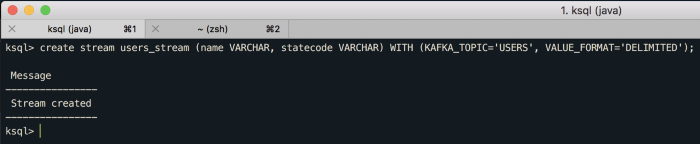
O comando acima irá criar um stream chamado “user_stream” baseado no tópico “USERS” e sabe que os dados virão separados por vírgula devido ao VALUE_FORMAT=’DELIMITED’.
Também estamos definindo dois campos para esse stream, o “name” e o “statecode”, ambos do tipo VARCHAR.
A partir disso, já é possível começarmos a criar consultas nesse stream. Sim, você não leu errado, são consultas! O KSQL tem uma notação muito parecida com o SQL para processarmos as mensagens.
Vamos criar a primeira consulta simples nesse stream, execute o comando abaixo:
select name, statecode from users_stream;
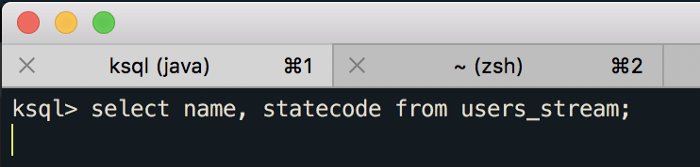
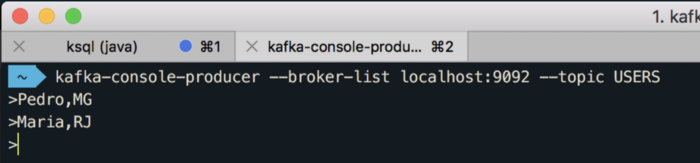
Nesse momento já estamos esperando pelas mensagens no tópico “USERS”. Vamos usar o kafka-console-producer para enviar algumas mensagens, no segundo terminal execute o comando abaixo e comece a enviar mensagens:
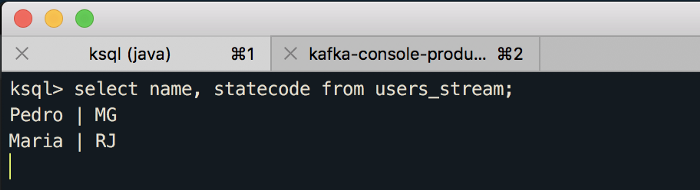
Se você voltar no primeiro terminal, verá que os dados já estão chegando no KSQL:
Como você pode imaginar, podemos criar algo um pouco mais “complexo”, como agrupar e saber quantas pessoas existem em cada estado, EXATAMENTE como faríamos em SQL:
select statecode, count(*) from users_stream group by statecode;

Repare que as duas mensagens anteriores não apareceram, mas é simples resolver, basta a gente pedir para o processamento começar do início das mensagens (reset do offset).
Para isso cancele a operação (Ctrl+C) e execute o comando:
SET ‘auto.offset.reset’=’earliest’;

Agora se você continuar a mandar mensagens no tópico “USERS” no segundo terminal, irá ver novas agregações sendo realizadas em real time! E, a partir desse resultado, poderíamos começar a tomar decisões diversas.
Veja aqui alguns exemplos bem legais de KSQL.
Conclusão
O resultado da consulta do KSQL pode ser enviado para um novo tópico que seria consumido por uma aplicação para executar a lógica de negócio resultante do processamento do stream, a vantagem é que todo o “trabalho sujo” ou “pesado” fica por conta do KSQL e não do seu sistema.
Quer se aprofundar no assunto?
Assista agora ao webinar onde aprofundo mais cada um dos tópicos e ensino o passo a passo de Como Processar dados Apache Kafka usando KSQL com uma aplicação diferente.