

Muitas aplicações estão sendo migradas da arquitetura monolítica para microsserviços. Essa mudança de paradigma se deve ao fato do microsserviço apresentar algumas vantagens em relação a aplicações monolíticas.
Entendendo as vantagens
Algumas dessas vantagens são: escalabilidade aprimorada, maior disponibilidade, heterogeneidade de tecnologia, entre outras. Por outro lado, esse novo modelo de arquitetura traz consigo alguns problemas até então pouco conhecidos.
Em aplicações monolíticas as chamadas aconteciam em memória, já em aplicações que seguem a arquitetura de microsserviços todas as chamadas são requisições em rede, logo percebe-se que se algum microsserviço estiver indisponível ou se a rede estiver respondendo com alta latência é possível que toda a aplicação pare de responder, causando uma falha geral do sistema.
Para que isso não aconteça é preciso que desenvolvedores e arquitetos encontrem meios de mitigar e tratar esses problemas.
Os padrões de resiliência atacam exatamente essas possíveis falhas de comunicação que acontecem entre microsserviços. Há vários padrões e cada um deve ser usado com um objetivo específico. Esses padrões também podem ser usados de forma combinada, ou seja, uma aplicação pode apresentar a implementação de mais de um desses padrões.
Embora exista vários padrões, nesse artigo vamos falar sobre o circuit breaker e bulkhead.
Circuit breaker e Bulkhead
A escolha por esses dois padrões se deu pelo fato do circuit breaker ser um padrão que permite o monitoramento da aplicação em tempo real, através desse monitoramento é possível identificar qualquer alteração de estado no circuit breaker, isso consequentemente ajuda a garantir a disponibilidade do microsserviço.
Além disso, esse padrão permite lidar com a indisponibilidade ou alta latência de um microsserviço sem comprometer a disponibilidade da aplicação.
Já o bulkhead proporciona a possibilidade de isolar funcionalidades críticas de um serviço, assim a falha em um microsserviço não tornará todas as funcionalidades de uma aplicação indisponíveis.
O que é Bulkhead?
Bulkhead é uma técnica usada na construção de navios, onde esse navio é dividido em seções, de modo que as seções possam ser vedadas e se houver uma violação no casco, apenas a parte danificada se encherá de água, não comprometendo todo o funcionamento do navio.
O mesmo conceito pode ser usado no desenvolvimento de microsserviços, onde partes são isoladas em pools para garantir que falhas em determinadas áreas não se propaguem para outras áreas. Através desse isolamento, busca-se garantir que a aplicação continue funcionando, mesmo que algum serviço não esteja disponível, ou esteja respondendo com alta latência no momento da requisição.
A biblioteca Hystrix da Netflix fornece uma implementação do padrão Bulkhead possibilitando limitar o número de chamadas simultâneas a um serviço, assim o número de solicitações na fila de espera é limitado melhorando a resiliência da aplicação. Quando não há uma implementação desse padrão, os encadeamentos podem se esgotar, causando um efeito cascata e podendo deixar a aplicação indisponível para todos os usuários.
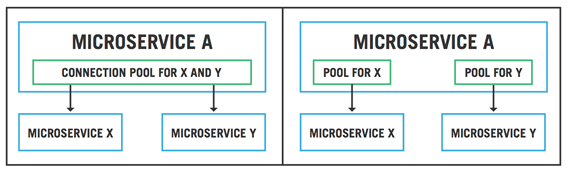
Na imagem acima podemos ver a ilustração de uma aplicação composta por microsserviços. No lado esquerdo temos uma implementação tradicional, sem nenhum padrão de resiliência, no lado direito temos a implementação do padrão bulkhead.
No lado esquerdo o microsserviço A faz requisições ao microsserviço X e ao microsserviço Y, compartilhando o pool de conexões entre eles. Se acontecer algum problema em X ou Y, toda a aplicação será afetada, já que o pool de conexões é comum.
Com a implementação do bulkhead, mesmo que o microserviço X falhe, apenas o pool para X será afetado. O funcionamento geral da aplicação não será afetado e os recursos do microsserviço Y continuarão disponíveis.
Quando esse padrão pode ser adotado?
· Para isolar consumidores críticos dentro da aplicação.
· Para que uma falha em um microsserviço não seja propagada para toda a aplicação.
· Quando se deseja rejeitar requisições para evitar sobrecarga na aplicação.
· Para dimensionar serviços de forma independente.
· Para isolar regiões geográficas e com isso melhorar o tempo de resposta da aplicação.
Lembrando que esse padrão não deve ser usado quando a disponibilidade de todos os microserviços forem essenciais para que a aplicação funcione de forma correta.
Circuit Breaker
O propósito desse padrão é evitar que a ocorrência de falhas de rede ou serviço seja propagada em cascata para outros serviços, melhorando assim a estabilidade e a resiliência da aplicação.
Dessa forma é possível que a aplicação continue disponível mesmo que algum serviço pare de responder ou responda com alta latência. Na prática, o circuit breaker funciona encapsulando chamadas para um serviço de destino e monitorando suas taxas de falha.
Aplicando esse padrão é possível proteger a chamada de uma função remota, quando o número de falhas em sequência ultrapassa um limite preestabelecido o circuit breaker desarma por um tempo determinado e o fluxo da aplicação passa a ser desviado para uma função de fallback, sem que a função com falha fique sendo chamada repetidas vezes, o que poderia levar a uma falha geral da aplicação.
Após o tempo limite expirar, o circuit breaker passa a permitir um número limitado de solicitações, em caso de sucesso nessas solicitações, o fluxo normal da aplicação é restabelecido. Se alguma falha voltar a ocorrer, o circuito é novamente aberto interrompendo o fluxo normal da aplicação mais uma vez.
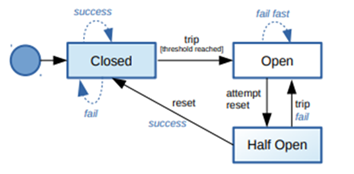
Esse padrão tem três estados: Closed, Open e Half-Open.
Closed
Quando não há falhas no sistema, o circuit breaker permanece fechado, assim todas as chamadas para os serviços são executadas normalmente. Se o número de falhas exceder um limite predeterminado, o estado muda para aberto.
Open
Neste estado, as solicitações não são encaminhadas para o serviço de destino. Nesse cenário é possível configurar um método de fallback, para onde as solicitações serão enviadas. O circuito pode voltar ao estado fechado, após o tempo limite se esgotar.
Half-Open
Após um período que o circuito foi aberto, o seu estado é alternado para Half-Open para testar se o problema original ainda ocorre. Se uma única falha ocorrer, o estado será alternado para aberto novamente. Se for bem-sucedido, ele volta ao normal, ou seja, o circuito é fechado e o fluxo normal da aplicação é restabelecido.

Circuit Breaker: Boas práticas ao aplicar o padrão
Caso tenhamos um serviço B indisponível ou respondendo com alta latência, o serviço A que chama o serviço B deve ser capaz de manter sua disponibilidade nesse cenário de falha. Para isso ele deve executar uma das seguintes ações:
· Fallback personalizado: O serviço A deve tentar obter os mesmos dados de alguma outra fonte. Como por exemplo, dados em cache. Se isso não for possível, uma mensagem de erro personalizada pode ser retornada pelo serviço.
· Falhar rapidamente: Se o serviço A souber que o serviço B está inoperante, ele não deve aguardar o tempo limite, já que isso levará ao consumo desnecessário de recursos de infraestrutura, degradando a performance da aplicação. Nesse contexto o fluxo da aplicação deve ser desviado imediatamente para uma rotina de fallback.
· Não travar: O serviço A não deve travar por causa da indisponibilidade do serviço B.
· Reparar automaticamente: Deve ser feita uma verificação periódica a respeito da saúde do serviço B.
Esse padrão pode ser adotado nas situações abaixo:
· Quando temos um serviço que tem que fazer chamadas a serviços externos.
· Para impedir que uma aplicação tente invocar um serviço remoto ou acessar um recurso compartilhado, se essa operação tiver grande probabilidade de falhar.
· Para se proteger de falhas de conexão de rede.
· Para evitar falhas em cascata.
E assim encerramos essa primeira parte super relevante no desenvolvimento de microsserviços. Ainda ficou com alguma dúvida no assunto? Deixa pra gente nos comentários!
Referências para se aprofundar no tema




