

Imagine os seguinte cenários
1. Sua aplicação para totalmente o processamento. Analisando a máquina, o uso de CPU, memória, rede e disco estão aparentemente normais, mas mesmo assim sua aplicação está “travada” e não está respondendo.
2. Algumas operações da aplicação estouram o temido OutOfMemoryError e não são concluídos ou até mesmo em alguns caso o processo da aplicação morre sem deixar nenhum tipo de rastro.
O que você faria nestes cenários?
Restartaria a aplicação? Talvez resolveria momentaneamente o problema, mas uma analise postmortem é necessária para que se corrija a raiz do problema.
Neste artigo quero te apresentar duas ferramentas que poderiam ser utilizadas para analisar e identificar as possíveis causas do problema: thread dump e heap dump.
Vou utilizar o VisualVM para apresentar as duas ferramentas, já que é uma aplicação que nos simplifica muito a vida, integrando várias ferramentas de CLI nos fornecendo uma interface gráfica amigável. Com o VisualVM você consegue visualizar o uso de heap, CPU, threads, classes carregadas e MBeans expostos, além de vários outras métricas.
Além de permitir também a instalação de plugins que aumentam as suas funcionalidades.
Algumas definições
GC – Garbage Collector
É um processo automático que gerencia tudo que está na memória, ele é responsável por liberar da memória heap instâncias que não estão mais sendo utilizadas.
Heap
É a área da memória RAM que a sua aplicação reserva, é lá que estará todos os objetos que você instância durante a execução da aplicação na JVM.
Pool de conexões (Connection Pool)
É uma forma de se gerenciar melhor as conexões, por exemplo, com o banco de dados.
Através dele você deixa um número mínimo de conexões abertas com o banco, o que reduz o tempo ao se fazer uma requisição, pois nem sempre será necessário abrir uma conexão nova quando precisar utilizar o banco, além de conseguir limitar a quantidade máxima de conexões, mas limitar pra que?
Bom, se sua aplicação fizer uma conexão com o banco para todo request, você pode imaginnar uma aplicação com 10000 usuários simultâneos. Isso seria 10000 conexões com o banco, o que incrementa muito o uso de memória da sua aplicação, podendo até causar um “estouro” da memória por não se ter um limite, além de sobrecarregar o banco (alguns bancos como o postgres faz um fork do processo para cada conexão).
Heap Dump
O heap dump nada mais é do que um snapshot ou uma “foto” da memoria heap da sua aplicação em um determinado instante. Com ele você consegue visualizar cada instância de objeto que está na memória naquele instante.
Ele é bem útil para se identificar memory leaks na sua aplicação, além da possibilidade de visualizar quais os objetos a sua aplicação instanciou e injetou na sua aplicação, te permitindo fazer um debug um pouco mais baixo nível quando as coisas começam a “magicamente” se comportar de forma estranha.
Para exemplificar, criei um projeto com spring boot com alguns problemas que vamos explorar, que pode ser encontrado neste repositório.
Nesse projeto temos uma única entidade Car na qual iremos trabalhar em cima.
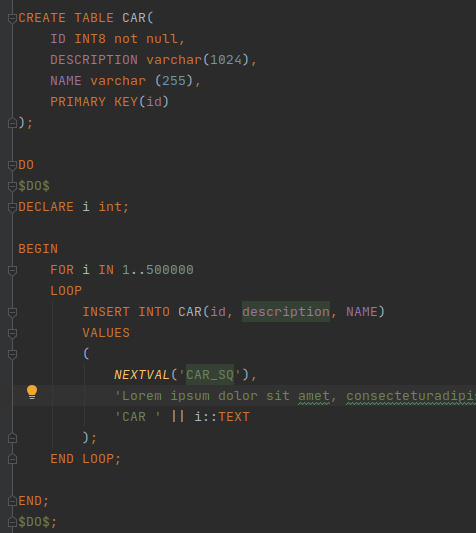
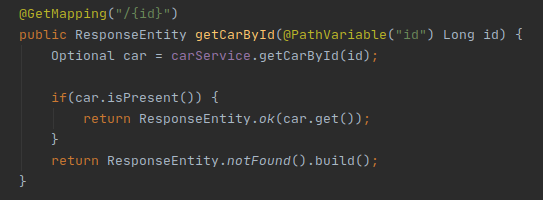
O primeiro que iremos analisar é uma API que carrega todos os Cars do banco, como podem ver na imagem acima, temos um campo que é uma string com 1024 caracteres.
Dentro do script de inicialização do banco estou populando também a tabela com 500.000 linhas, que possuem uma description com 1024 caracteres. Agora vamos fazer algumas contas, com 500.000 Cars * 1024 caracteres = 512.000.000, simplificando um pouco nosso cenário vamos assumir que cada caractere utiliza apenas um byte na memória (para suportar vários encodes a implementação de String no Java utiliza um array de bytes e não mais um simples char), então temos 512MB apenas para carregar todos as descrições dos Cars na memória.
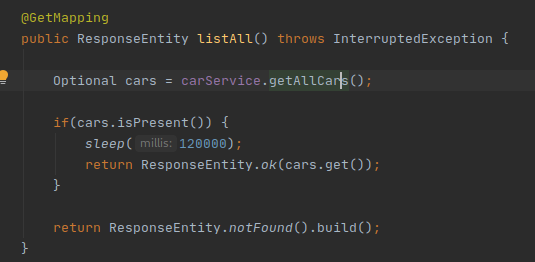
Na próxima imagem você pode ver o código que vai fazer essa busca! Coloquei um sleep antes de dar a resposta para que possamos ter mais tempo para visualizar a heap.
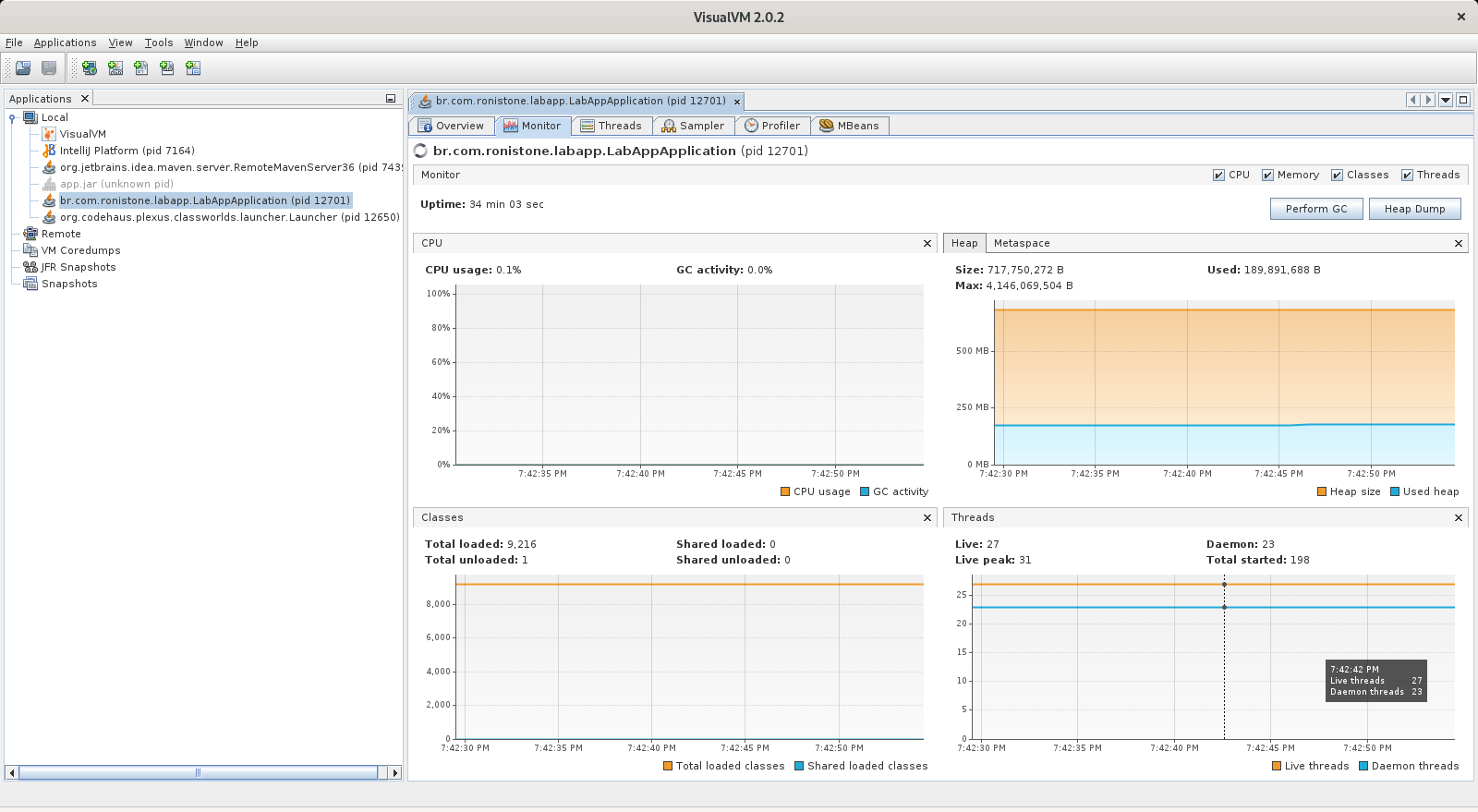
Na próxima imagem, dentro VisualVM podemos ver como está nossa aplicação antes de realizar qualquer requests na API, nossa heap utilizando algo entorno de 190MB. Acima do gráfico da heap podemos ver o mágico botão que nos gera o Heap Dump.
Vou gerar um heap dump antes e depois para comparação.
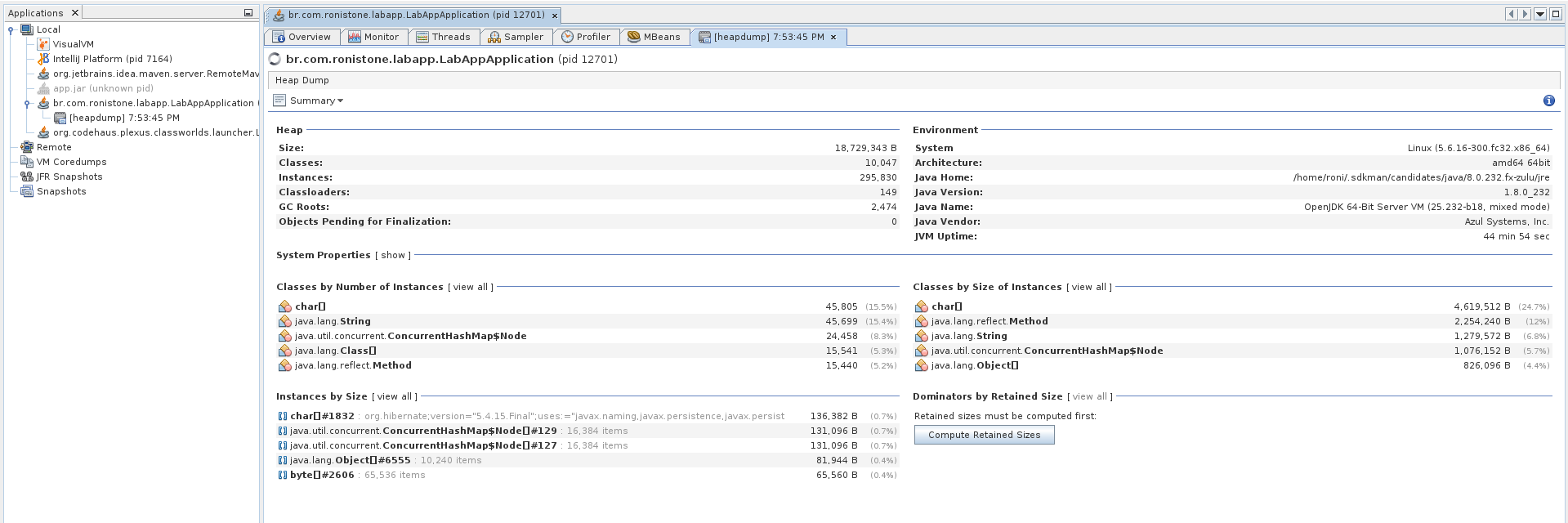
Na tela inicial já temos algumas informações interessantes sobre a heap, por exemplo, o tamanho, número de classes, número de instâncias e classloaders que estão na heap naquele momento.
Como podem ver a heap está com cerca de 18MB apenas, no momento em que fiz o dump o GC limpou a heap o que causou essa diferença.
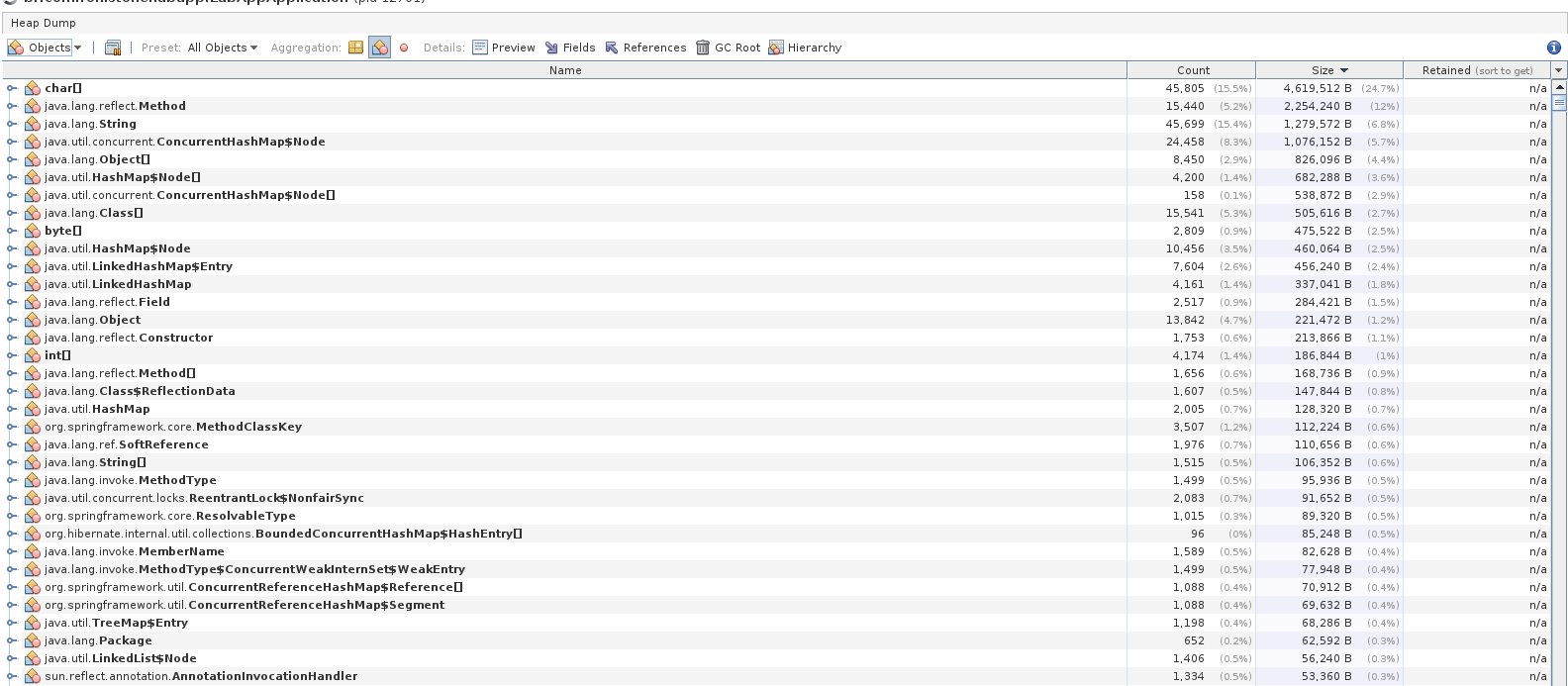
Se sairmos do summary e selecionar o objects, temos uma lista dos objetos na heap e podemos “navegar” dentro deles e ver valores de campos internos, quem referencia aquele objeto além de quantidade de memória gasta e quantidade de instâncias.
Veja que temos cerca de 45.000 string e arrays de char. Após fazer a request teremos o seguinte cenário:
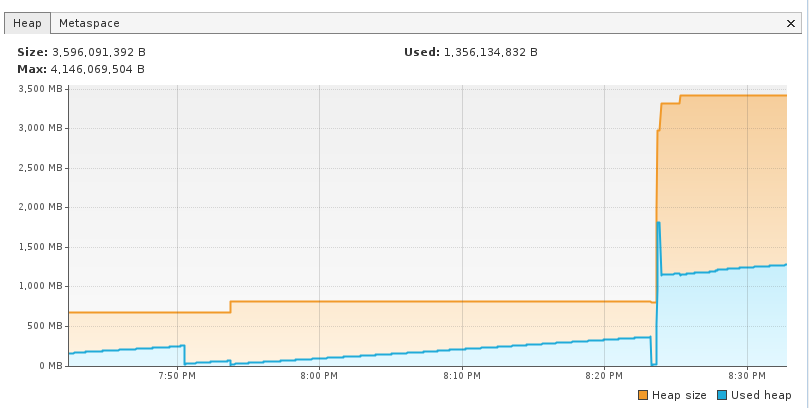
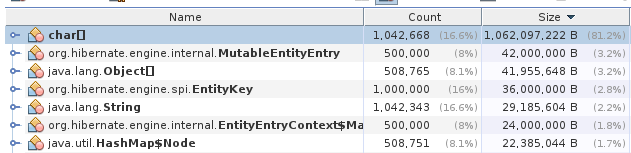
Com as imagens acima podemos ver que o uso da heap chegou a um pico de 2GB e depois estabilizou em cerca de 1.3GB, o que permaneceu até mesmo depois da resposta ser enviada (e só será liberada quando uma execução do GC for realizada).
Outra ferramenta muito útil que o VisualVM nos fornece ao analisar um heap dump, é a barra de busca na parte de baixo da tela de objects.

Com ela você poderia, por exemplo, analisar o cenário que citei em que você tem uma injeção de dependência acontecendo e precisa identificar se a injeção aconteceu e caso tenha acontecido se foi feita injetado a dependência correta. Apenas visualizando se existe a classe, ou seja, se algum classloader carregou aquela classe, para isso basta que ela aparece nessa lista do objects, e se há instancia olhando o count daquela classe. Além de poder ver quem referencia determinada classe, como nesta imagem:

Nela podemos ver que o CarServiceImpl é referenciado pelo controller e em um hash map que gerencia os beans instanciado pelo spring.
Uma funcionalidade da JVM interessante para se ter informações em casos de OutOfMemoryError, é habilitada utilizando estes dois parâmetros
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/jvm/heapdump_$DATE_START.hprof
Isso irá fazer com que sua aplicação gere um Heap dump quando acontecer um OutOfMemory, o que te dará informações caso sua aplicação em produção pare de forma misteriosa.
Vamos agora utilizando esses parâmetros e forçar um OutOfMemoryError. Para isso vou utilizar o parâmetro -Xmx100m que irá limitar o tamanho máximo da minha heap em 100MB, esse é o comando na integra que utilizei:

Com a aplicação em pé, essa é a nossa heap:
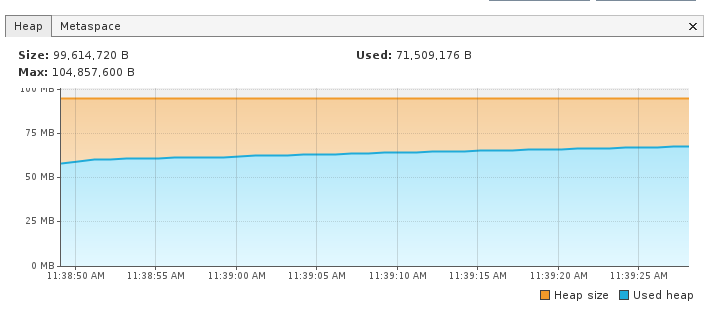
Após fazer o request na nossa API, acontece uma queda brusca na utilização da heap, pois no request é lançado um java.lang.OutOfMemoryError retornando 500 para o cliente e o GC entra em ação limpando a heap.
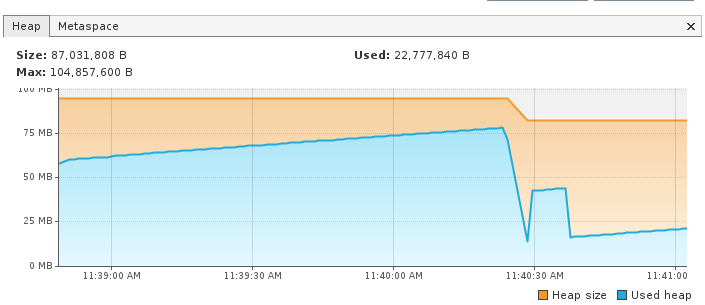

E esse é o comportamento da aplicação com o estouro da heap, sem os parâmetros de heap dump da JVM estaríamos no escuro com muito pouco ou até sem ter qualquer tipo de informação sobre a falha.

Thread Dump
Como o heap dump é um snapshot da memória, o thread dump é um snapshot das threads da sua aplicação, com ele você tem acesso ao stacktrace de cada thread, você consegue visualizar todo o estado da sua aplicação e identificar possíveis gargalos ou até mesmo deadlocks que podem acontecer.
Para ilustrar, na nossa aplicação existe uma busca pelo ID do Car, nesta busca eu inseri propositalmente um sleep no SQL que a aplicação vai executar no nosso banco de dados.
Isso irá simular uma lentidão e consequentemente uma falta de conexões com o banco disponíveis travando completamente qualquer interação com o banco de dados.

Para forçar a falta de conexões limitei o pool para o máximo de 2 conexões (hikari é o pool de conexões default no spring boot), e também defini o tempo de espera por uma conexão para 60 segundos, ou seja, toda request que chegar após o limite de 2 conexões irá aguardar 60 segundos e caso não consiga pegar uma conexão será lançado uma exception.

Com tudo isso definido, podemos dar uma olhada no VisualVM. Agora iremos utilizar a aba Threads:
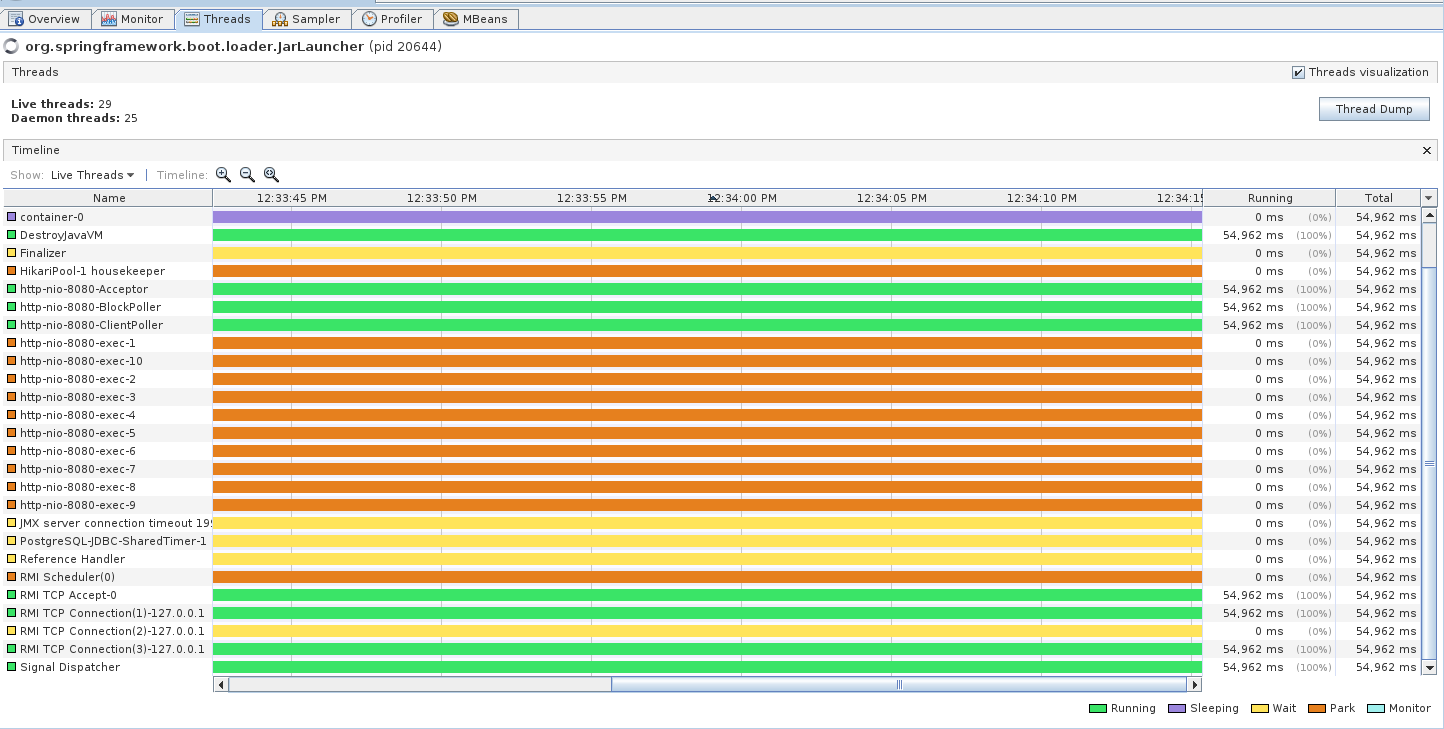
Nessa aba você consegue ter uma visão de todas as threads que existem na sua aplicação, é bem interessante pois você consegue identificar threads que estão executando sem parar ou que estão paradas esperando algum recurso. Por exemplo, após fazer uma request temos o seguinte:

A thread http-nio-8080-exec-1 entra em Running até finalizar a busca e conseguir dar resposta para o cliente. Vamos agora mandar várias requisições para a aplicação e ver o que acontece.


Podemos ver que temos apenas duas threads em execução e as outras estão no estado park aguardando uma conexão com o banco liberar. Outro comportamento que podemos notar é o thread pool do nosso servidor de aplicação abrindo várias threads para tratar as requisições, da mesma forma que existe um pool de conexões com o banco, nossa aplicação também possui um pool de threads que tem uma ideia parecida, mas agora o recurso que ele gerencia são threads e não conexões com os banco de dados.
Já vimos o comportamento das threads, agora vamos ao Thread Dump. Irei fazer várias requisições e gerar o thread dump clicando no botão “Thread Dump” que existe na aba Threads do VisualVm.
Feito isso você será levado para tela do thread dump:
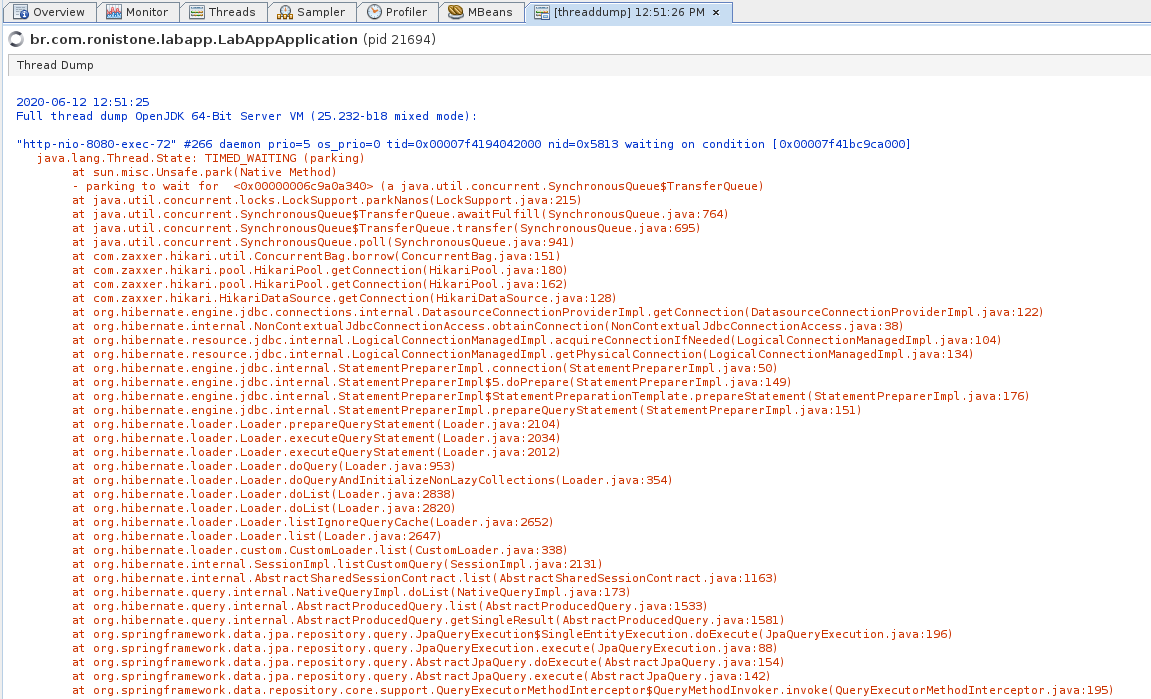
Agora temos tem uma visão geral dos stacktraces de todas as threads da nossa aplicação, mas é um pouco ruim de se analisar nessa tela então vamos copiar tudo e jogar em uma arquivo, nessa tela os comandos ctrl+a e ctrl+c funcionam, então utilize eles para selecionar tudo e copiar. Feito isso vamos utilizar o site fastthread.io para analisar o nosso thread dump melhor. Basta enviar o arquivo que você salvou ou utilizar a opção raw e colar o thread dump e clicar em analyze.
Feito isso você verá uma tela parecida com essa:
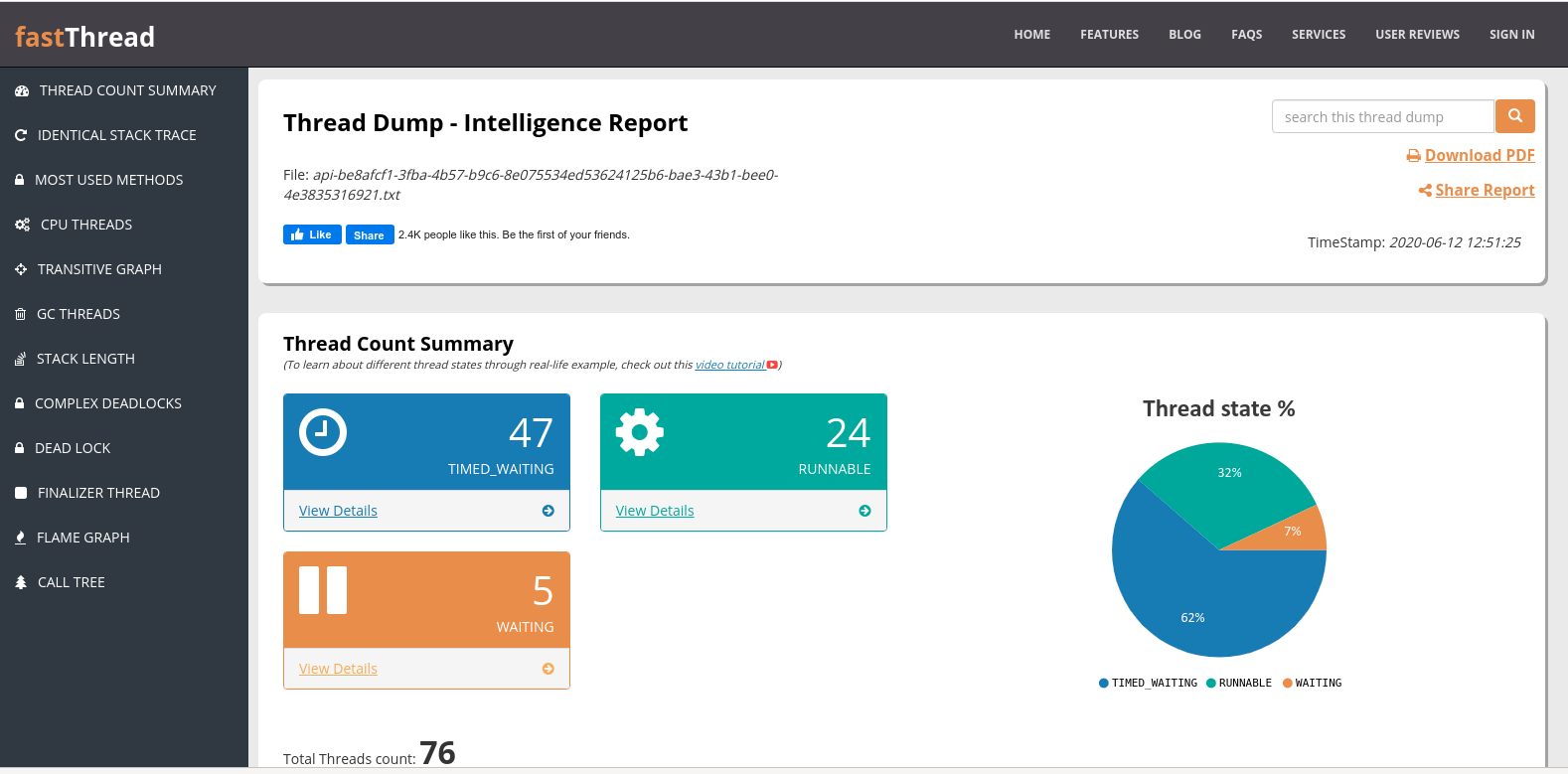
De cara já temos informações dos estados das threads da aplicação. Como tínhamos visto no visualvm, apenas 2 threads ficavam em running e o restante ficava em park, aqui vão ser mostradas como timed_waiting, então vamos descer e explorar um pouco, logo abaixo temos uma visão das threads agrupadas. Podemos ver que temos 46 threads http ou seja 46 thread que tratam requisições http que chegam na nossa aplicação.
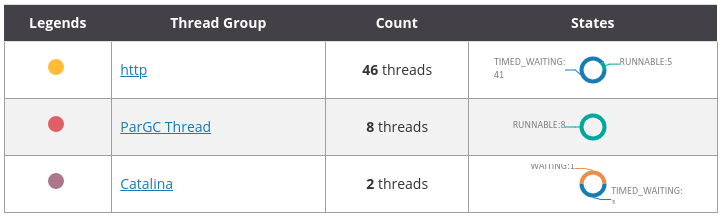
Um pouco mais abaixo, o FastThread tem um agrupamento das threads por stacktrace idênticos, isso é bem interessante pois pense, todas as threads que estão esperando uma conexão, como foi requisições no mesmo serviço, terão o mesmo “caminho” dentro da nossa aplicação. E as outras que conseguiram adquirir um conexão com o banco terão também um mesmo stacktrace.
Com isso em mente vemos que temos 41 threads em timed_waiting com o mesmo stacktrace, um forte candidato as thread que não conseguiram conexão, abrindo o stacktrace completo podemos ver o seguinte:

Podemos ver ali um getConnection acontecendo no hikari, o que para em um park() que para a nossa thread aguardando a liberação de uma conexão. Agora vamos procura nossas outras 2 threads que conseguiram uma conexão.
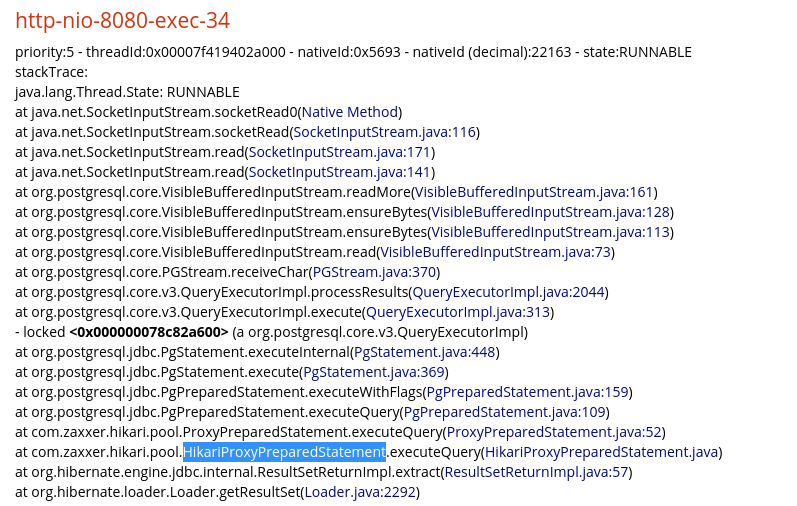
E cá estamos, as threads estão paradas em um socketRead esperando resposta do nosso banco de dados.
Conclusão
Tudo isso para que possamos visualizar o estado da aplicação! Estes foram exemplos simples, mas são ferramentas com um poder muito grande. Não apenas é muito importante entender como sua aplicação funciona e ter informações em cenários de falhas, para que se resolva rapidamente e reduza os riscos para o negócio, como para um desenvolvedor otimizar algo que está desenvolvendo e reduzir possíveis custos.
Estas ferramentas funcionam para aplicações sobre a JVM, então poderiam ser utilizadas além do Java com por exemplo Kotlin, a aplicação que utilizamos neste artigo foi escrita tanto em Java como em Kotlin.
Posso citar por exemplo um caso em que utilizei o Thread Dump para identificar gargalos em uma aplicação que fazia um processamento pesado para cada request que chegava, e estava limitada a cerca de 300 requests simultâneos. Através dos stacktrace identifiquei a aplicação fazia várias leituras de arquivo em um único request pois todas minhas threads http paravam em uma leitura, então eu tinha informação de onde atacar para resolver o problema e reduzir a latência da aplicação, além de melhorar o throughput, que subiu para casa de milhares de requests simultâneas.
Quando estou procurando realizar alguma otimização nas minhas aplicações sempre penso o seguinte: não adianta otimizar algo que represente por exemplo 10% do custo de algo se eu tenho um outro problema que represente 90%. Uma otimização pode ser muito mais impactante se for feita no local correto, além de recursos que podem ser economizados.
E você, quero saber sua experiência no assunto. Se ainda ficou com alguma dúvida, deixe nos comentários! Essa troca é muito importante pra nossa comunidade.




