

Gerenciar dados e gerar valor com eles são grandes desafios comuns a muitas empresas. Mas e se eu te dizer que existe um novo paradigma que nos ajuda a resolver este problema? Pois o Data Mesh se propõe a isso e a muito mais!
Quer conhecer o que é Data Mesh e seus princípios, além de uma baita contextualização sobre sobre o trabalho com dados nas empresas desde a década de 60? Então continue lendo!
Gerar valor com dados: o desafio
Você já sentiu que seu produto e/ou projeto perde a velocidade quando você precisa modelar e analisar os dados? Ou que ao passo que as tecnologias de Big Data ficaram melhores e acessíveis, provar o valor do uso destas tecnologias e efetivamente obter valor dos dados ficou mais difícil?
Neste artigo, vamos falar sobre estes problemas, começando pelo cenário atual, passando pelas arquiteturas clássicas e apresentando uma nova arquitetura que pode ajudar no sucesso de produtos e/ou projetos de dados.
Vamos usar como referência a arquitetura Data Mesh, criada pela Zhamak Dehghani e publicada em dois artigos no blog do Martin Fowler (links nas referências).
Contexto executivo
Mesmo sendo um assunto comum nas agendas das organizações (99% investindo em dados, 65% definindo CDOs e 96% reportando impactos de dados nos negócios), produtos e/ou projetos de dados ainda têm uma baixa taxa de sucesso (39% trabalhando com dados como ativos e 24% reportando uma cultura data-driven). Fonte: NewVantage Partners Releases 2021 Big Data and AI Executive Survey.
Colocando de forma simples, as organizações têm um alto investimento, mas pouco sucesso em iniciativas de dados.
Pensando neste cenário, foram identificadas quatro dificuldades-chave, definidas como modos de falha:
- Fail to bootstrap: dificuldade em dar os primeiros passos, desenhar a arquitetura, escolher as tecnologias e criar a infraestrutura inicial;
- Fail to scale sources: dificuldade em escalar com a proliferação de novas fontes de dados, tanto em quantidade quanto variedade;
- Fail to scale consumers: dificuldade em escalar com a proliferação de novos padrões de consumo, tanto ferramentas quanto cargas de trabalho;
- Fail to prove data-driven value: dificuldade em justificar e/ou obter retorno dos investimentos nas iniciativas de dados.
Com o contexto executivo e os modos de falha definidos, podemos analisar melhor como as arquiteturas estabelecidas funcionam, e se elas podem ter relação com estes problemas.
Contexto tecnológico
Para entender o contexto tecnológico e potencialmente identificar as causas dos problemas do contexto executivo, vamos revisar as diferentes gerações de arquiteturas de dados:
Data Warehouse, 1960s, 1st gen
Na primeira geração, o contexto executivo tinha um ritmo mais lento, mais previsível e era guiado por grandes corporações de tecnologia. A arquitetura de tecnologia era composta por sistemas grandes, complexos e pouco integrados.
O desafio era conseguir uma visão unificada entre estes sistemas (incluindo entender os contextos de negócio), diferentes tecnologias, formatos de dados proprietários e controle de acesso.
Neste cenário, a arquitetura de dados se adaptou através de processos de ETL (Extract Transform Load), técnicas de modelagem, documentação/metadados e usando ferramentas e tecnologias proprietárias, otimizadas para rodar em servidores grandes e caros.
Os times responsáveis pela arquitetura de dados eram especializados e centralizados.
Data Lake, 2010s, 2nd gen
Já na segunda geração, o contexto executivo era mais dinâmico, menos previsível e era guiado não apenas pelas grandes corporações, mas também por empresas novas e disruptivas.
A arquitetura de tecnologia evoluiu para um maior número de aplicações (elementos menores que sistemas), mais simples e integradas, estimulada pelo uso da cloud, containers, microservices e service mesh.
Neste cenário, a arquitetura de dados se adaptou através do uso de conceitos de computação distribuída, puxada pelos clássicos papers do Google (MapReduce, GFS e BigTable), novas técnicas de modelagem, modernização dos processos de documentação/metadados e usando tecnologias e formatos de armazenamento de código aberto, otimizadas para rodar em servidores menores e mais baratos.
Os times responsáveis pela arquitetura de dados continuam especializados e centralizados.
Híbrida, 2020s, 3rd gen
Na terceira e atual geração, o contexto executivo tem um ritmo cada vez mais acelerado e dinâmico, onde as empresas e organizações com maior capacidade e velocidade de inovar e se adaptar direcionam o mercado.
A arquitetura de tecnologia continua evoluindo sobre os pilares da geração anterior (cloud, containers, microservices e service mesh) e incorporando data, analytics e machine learning como elementos essenciais.
Neste cenário, a arquitetura de dados se adaptou para o uso de cloud, unificação de processamento batch e streaming, real-time analytics, ainda tornando mais simples o uso de machine learning.
A maioria dos times responsáveis pela arquitetura de dados continuam especializados e centralizados.
Principais problemas para trabalhar com dados
Analisando as arquiteturas somadas aos problemas identificados no contexto executivo, a autora identificou três principais problemas:
- Arquitetura monolítica: talvez baseadas na premissa que para se obter valor dos dados, era necessário ter todos os dados em um único lugar, as arquiteturas de dados sempre foram complexas e centralizadas, focadas em pessoas e processos. Mesmo sendo complexas, era relativamente simples começar um Data Warehouse ou Data Lake, mas muito difícil de escalar, acompanhando o ritmo de crescimento orgânico dos usuários e projetos de dados;
- Decomposição acoplada com ETL: talvez pela falta de pensamento de produto e foco no cliente, os times de dados organizavam as pessoas e processos usando partições técnicas (extrair, transformar, carregar, modelar, governar), criando uma experiência ortogonal (com muitos atritos) para seus usuários, aumentando muito o custo e tempo necessários para rodar um projeto de dados;
- Responsabilidade muito especializada e centralizada: com arquiteturas complexas e pessoas/processos baseados em partições técnicas, a responsabilidade das arquiteturas de dados ficaram exclusivamente nas mãos de poucas pessoas muito especializadas, com pouca autonomia para clientes, criando um grande gargalo para projetos de dados.
Em resumo, historicamente as arquiteturas de dados eram essencialmente complexas, centralizadas e dependentes de poucas pessoas, difíceis de encontrar, com alto custo e tempo para subir projetos de dados e baixa autonomia para os usuários.
Observando os contextos e potenciais problemas, a autora criou uma teoria (declaração de causalidade) através de uma arquitetura referência, com o objetivo de aumentar o sucesso dos projetos de dados.
Olá, Data Mesh!
O processo criativo não está limitado à criação de novos elementos, mas também à combinação de elementos existentes para resolver novos problemas. No Data Mesh, o novo não está na criação de tecnologias e/ou ferramentas, mas sim na combinação de conceitos e práticas consolidadas, criando uma nova abordagem para trabalhar com dados:
- Data: pensar dados como cidadãos de primeira classe, como parte essencial da estratégia executiva e tecnológica. Podemos observar esta tendência na relação entre a capacidade das empresas usarem dados como diferenciais competitivos e seus resultados no mercado;
- Product thinking: pensar dados como produtos, não como projeto ou serviço, oferecendo uma ótima experiência para os usuários. Podemos observar esta prática se consolidando em produtos com funcionalidades incríveis, cada vez mais simples de usar;
- Distributed domain driven design architecture: pensar dados como parte dos domínios de negócio, distribuindo efetivamente a autonomia e responsabilidade. Podemos observar esta nova arquitetura ganhando espaço junto com Domain-driven design (DDD), microservices e service mesh;
- Self-service platform design: reduzir a carga cognitiva dos usuários com padrões, protocolos, tecnologias e ferramentas agnósticas de domínio, disponíveis em uma plataforma de autosserviço. Podemos observar estas plataformas sendo possíveis com o uso intensivo de containers e aumento da oferta e redução de custos da nuvem.
Princípios do Data Mesh
Com a fundação da nova arquitetura definida, podemos entender como construir as paredes, através de 4 princípios essenciais.
Princípio 1 – Domain Ownership
O primeiro e mais importante princípio do Data Mesh é mover a propriedade dos dados de um único time centralizado para muitos times distribuídos nos domínios de negócio. Ao fazer isso, podemos observar algumas vantagens, incluindo:
- Usar os dados perto das fontes, ao invés de movimentar dados: movimentar os dados tem dois custos relevantes. Primeiro, complexidade de operação, caso seja necessário adicionar mais jobs de processamento no workflow de dados, e assumindo que cada novo job é um potencial ponto de falha. Segundo e mais importante, a semântica (significado) dos dados tender a diminuir nestas movimentações, principalmente na movimentação entre times;
- Usar a cópia mais relevante, ao invés de tentar manter uma única cópia: o esforço necessário para manter uma única cópia dos dados é maior do que o resultado, sendo comum existir uma falsa sensação de controle, enquanto as pessoas continuam criando suas cópias “fora do radar”. Mover o esforço dos processos de controle e auditoria para criar um modelo de relevância e gerenciar melhor o ciclo de vida dos dados permite usar os próprios clientes e times de governança como reguladores orgânicos, distribuindo também a responsabilidade;
- Dados distribuídos por domínios, ao invés de partições técnicas: ao distribuir os dados por domínio, balanceamos a gravidade dos dados, que antes ficavam concentrados em alguns times, normalmente organizados por estágios do processo de ETL. Ao balancear a gravidade dos dados, temos um modelo de escala orgânica, alinhados com o padrão de crescimento de negócio, respondendo melhor à proliferação de novas fontes de dados e casos de uso.
No final do dia, este princípio é essencial para escalar no mesmo ritmo de crescimento das fontes e de quem consome os dados.
Princípio 2 – Data as Product
Distribuir a propriedade dos dados nos domínios é uma ideia interessante e habilita um modelo de crescimento mais orgânico. Por outro lado, algumas garantias do modelo centralizado são perdidas, por exemplo, a padronização no acesso e qualidade dos dados.
Para equilibrar o modelo distribuído e a necessidade de dados acessíveis e com qualidade, é necessário pensar nos dados como produtos, incluindo:
- Novas funções, Data Product Owner e Data Developer: duas novas funções nascem com o modelo distribuído, para assumir a responsabilidade pela definição e desenvolvimento dos produtos de dados. Ao invés de pensar nos dados apenas como ativos ou como serviços, Data Product Owners aplicam o pensamento de produto para criar a melhor experiência para clientes, enquanto Data Developers trabalham com foco em desenvolver o produto:
- Dados acessíveis, documentados e disponíveis: ao pensar nos dados como produtos, as pessoas responsáveis pensam mais na experiência dos usuários, incluindo definir como os dados serão acessados (como uma tabela em um Data Warehouse ou como um streaming de dados real-time), documentar melhor os dados, incluindo sintaxe e semântica, tendo em vista que qualquer dificuldade para entender os dados agora são de responsabilidade do próprio time, e não de um time terceiro;
- Dados confiáveis, verificados e rastreáveis: ainda, ao pensar nos dados como produtos, as pessoas responsáveis não precisam apenas garantir que os dados estejam acessíveis, documentados e disponíveis, mas também garantir a qualidade destes dados. Esta qualidade inclui garantir que os dados venham de fontes verificadas e que todos os processos relacionados aos dados sejam rastreáveis, evitando problemas com dados incompletos e/ou incorretos.
No final do dia, este princípio é sobre oferecer uma ótima experiência para que os usuários possam descobrir, entender e usar dados de alta qualidade.
Princípio 3 – Self-service Data Platform
Ao distribuir a propriedade dos dados entre os domínios, existe o risco de pulverizar todo o conhecimento, habilidade e tecnologias de dados, antes concentrada em um único time.
Esta pulverização aumentaria a carga cognitiva dos times de domínio e criaria muito trabalho duplicado. Neste cenário, pensar no time centralizado não mais como um monolito, mas como uma plataforma de dados agnóstica de domínio, incluindo:
- Novas funções, Data Platform Product Owner e Data Platform Engineer: estas novas funções são responsáveis não mais pelos dados específicos de domínio, mas têm um novo objetivo: oferecer a melhor experiência para criar produtos de dados, reduzindo a carga cognitiva dos times de domínio. Data Platform Product Owners identificam e criam jornadas com foco no cliente, enquanto Data Platform Engineers usam seu conhecimento e habilidade para criar tecnologias que possam ser usadas por todos os domínios;
- Plano de desenvolvimento, criar, versionar e publicar produtos de dados: oferecer a melhor experiência para Data Developers do domínio criarem e publicarem seus produtos de dados, incluindo stacks de processamento de dados, pipelines para integração e entrega contínua;
- Plano de infraestrutura, conectividade, armazenamento, processamento: reduzir a carga cognitiva de Data Developers, oferecendo infraestrutura de dados pronta para usar. Infraestrutura de dados inclui: conectividade de rede garantindo que nenhum Data Developer precise configurar redes, rotas ou firewall, armazenamento poliglota como storage de objetos, tabelas e streaming de dados, e infraestrutura para processamento de jobs e criação de workflows tolerantes à falhas.
No final do dia, este princípio é sobre garantir que os times dos domínios possam criar e consumir produtos de dados com autonomia, usando as abstrações da plataforma.
Princípio 4 – Federated Computational Governance
Aplicando os princípios anteriores, os times dos domínios usam uma plataforma de dados de autosserviço para criar seus produtos de dados. Mesmo equilibrando autonomia e responsabilidade, em um modelo de produtos e times distribuídos mas isolados, não é possível extrair o máximo valor dos dados, é necessário ter interoperabilidade. O desafio é criar um modelo de governança federada, que equilibre descentralização e centralização, incluindo:
- Adotar federação, compartilhar a responsabilidade: tradicionalmente, times de governança usam um modelo centralizado de regras e processos, e acumulam toda a responsabilidade para garantir padrões globais para os dados. Neste novo modelo, o time de governança muda sua abordagem para compartilhar a responsabilidade através de federação, sendo responsável por definir, por exemplo, quais são as regras globais (não locais) para qualidade e segurança de dados, ao invés de ser sozinho responsável pela qualidade e segurança de todos os dados da empresa. Pensando em LGPD, o time de governança global continua sendo o responsável legal e pode inspecionar os domínios para garantir as regras globais;
- Definir sintaxe e semântica: definir modelos globais para identificar e dar significado aos dados, incluindo padrões para nomes de tabelas e colunas, taxonomia, elementos de metadados e políticas de controle de acesso;
- Definir padrões e protocolos de interoperabilidade: criar padrões e protocolos para garantir a interoperabilidade, definindo interfaces comuns para acessar os dados, usando formatos de armazenamento e compartilhamento de dados abertos, embutidos na plataforma de autosserviço, sem a necessidade de processos manuais.
No final do dia, este princípio é sobre permitir que os usuários obtenham valor a partir de interoperabilidade entre produtos de dados, seguindo padrões e protocolos globais.
Arquitetura resumida do Data Mesh
Na arquitetura resumida, é possível observar os quatro princípios em alto nível, começando com a plataforma de dados de autosserviço por baixo, passando pelos domínios agora responsáveis não apenas pelas aplicações operacionais, mas também pelos dados, tudo isso sob o “guarda-chuva” da governança federada, garantindo a interoperabilidade dos produtos:
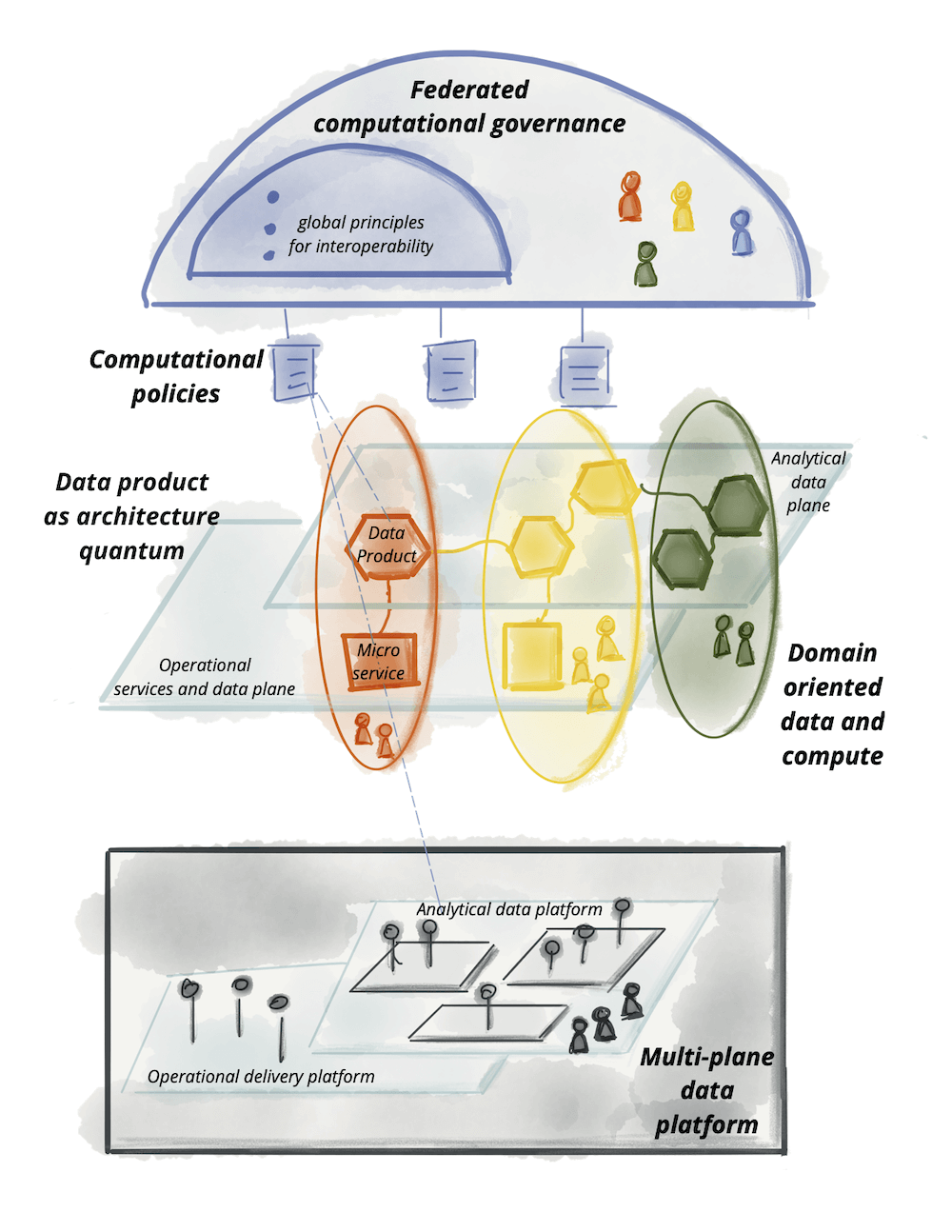
Um aspecto muito importante da arquitetura é que os produtos de dados são quantuns de arquitetura, ou seja, eles são autônomos, e incluem: código, dados, metadados e infraestrutura para conectar, processar e armazenar dados. Tudo isso dentro do domínio de negócio, mais perto da fonte da verdade.
Adoção do Data Mesh
Desde 2020, o Data Mesh têm se tornado assunto comum nos eventos e conferências relacionadas à dados e negócios, e também nas redes sociais como Twitter e LinkedIn, usando a hashtag #datamesh.
As clouds têm se movimentado também para facilitar a implementação da arquitetura, oferecendo serviços e abstrações para acessar dados entre diferentes contas ou projetos, melhorando seus produtos relacionados à governança (metadados, catálogo, controle de acesso) e processamento e armazenamento de dados.
Alguns cases relevantes e de diferentes mercados foram compartilhados, incluindo Netflix, Yelp, Zalando e JP Morgan (mais detalhes nas referências).
Na Zup, usamos o Data Mesh como arquitetura de referência para projetos e produtos internos e externos. Temos observado bons resultados, principalmente na velocidade para começar a usar os dados.
Além disso, estamos entendendo na prática como distribuir a responsabilidade dos dados impacta estes projetos e produtos e principalmente, a dinâmica de trabalho dos times.
Conclusão
Mesmo com alto investimento e sendo um assunto comum nas empresas, as iniciativas de dados têm uma baixa taxa de sucesso. Analisando o contexto de negócio e de tecnologia, identificamos que a arquitetura atual apresenta modos de falha que criam atrito para o crescimento orgânico do negócio, principalmente por ser baseado em uma arquitetura e times centralizados.
Ao distribuir a propriedade e responsabilidade dos dados entre os domínios de negócio, reduzimos este atrito, e aplicando os princípios do Data Mesh, conseguimos garantir a qualidade dos dados, reduzir o esforço cognitivo dos times e garantir interoperabilidade entre os produtos de dados de uma empresa.
A visão de dados da Zup é alinhada com este paradigma, reforçando a visão customer centric e de crescimento exponencial das empresas, baseado em um modelo de escala que acompanha organicamente o crescimento do negócio.
Curtiu? Então deixe seu comentário e/ou compartilhe este artigo.
Referências
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh – Site do Martin Fowler
- Data Mesh Principles and Logical Architecture – Site do Martin Fowler
- NewVantage Partners Releases 2021 Big Data and AI Executive Survey – Business Wire
- Data Mesh @ Yelp – 2019 (slideshare.net)
- Netflix Data Mesh: Composable Data Processing – Justin Cunningham – YouTube
- Data Mesh in Practice – Arif Wider & Max Schultze – NDC Oslo – YouTube
- How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform – AWS Big Data Blog




