

Este é o segundo post de uma série sobre estruturas de dados probabilísticas e hoje iremos abordar o Bloom Filter.
O principal objetivo dessa série é trazer maior clareza sobre o que é e como podemos utilizar esse tipo de estrutura de dados, trazendo ganhos de performance e também reduzindo custos de nossas aplicações.
Conhecendo o bloom filter
O bloom filter talvez seja a mais conhecida e utilizada das estruturas probabilísticas e tem um funcionamento simples de ser entendido. Seu objetivo é bem definido, podemos afirmar que o bloom filter busca sempre responder a questão: “O elemento existe dentro da coleção de dados?”
Diferente de um mapa ou um set, o bloom filter não precisa armazenar todo o conteúdo do elemento para verificar se ele existe ou não em uma coleção. Assim, isso é realizado através de funções hash e uma das vantagens desse comportamento é que ele faz com que seja utilizado uma quantidade bem menor de espaço em memória.
O Bloom filter é formado por uma quantidade K de funções Hash e um array de bit de tamanho M que irá guardar o resultado obtido por cada hash.
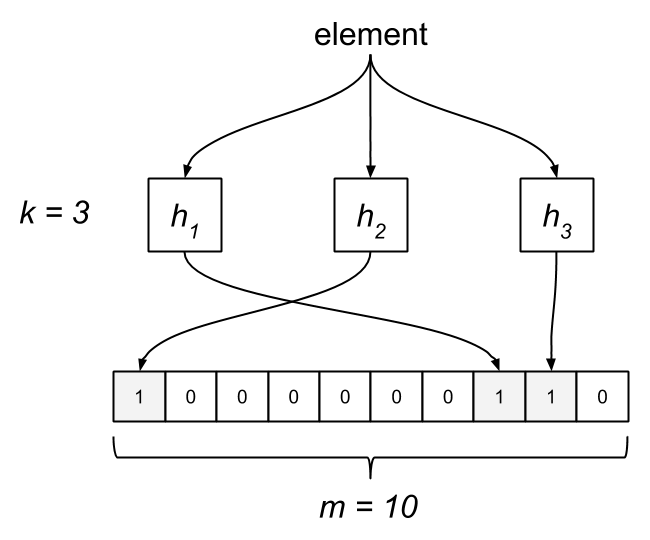
Cada função hash recebe um elemento de entrada, processa isso e retorna uma posição no array de bit a qual deve ser gravado o valor 1. Ao consultar um elemento, o bloom filter irá processá-lo com as mesmas funções hash e caso todas as posições retornadas pelas funções hash estejam com o valor 1 podemos presumir que esse elemento existe dentro da coleção.
É importante informar também que não é possível excluir um elemento do bloom filter uma vez que esse elemento foi incluído. Caso isso seja necessário, o filter deve ser gerado novamente apenas com os elementos presentes.
Mas e se dois elementos diferentes gravarem o array de bit com 1 na mesma posição?
Bom como explicado no post anterior, as estruturas de dados probabilísticas podem retornar com falsos positivos, e esse é o cenário em que o bloom filter pode gerar falsos positivos.
É possível diminuir a frequência de falsos positivos brincando com os valores de K e M. Quanto mais funções hash existirem e quanto maior o tamanho do array M, menor são as chances de ocorrer uma colisão de valores. Porém, isso irá exigir mais processamento e mais memória do seu bloom filter.
Outro fator importante que percebemos do comportamento do bloom filter é que ele nunca irá retornar um falso negativo. Em outras palavras, ele nunca irá dizer que o elemento não existe na coleção sendo que na verdade existe.
Exemplo prático
Imagine que você é um engenheiro de software dentro de uma instituição bancária. Dentre suas várias atribuições, você é responsável por um software que tem como objetivo prevenir fraudes nas transações que passam todos os dias pela instituição.
Entre as várias regras de negócio do seu software de prevenção a fraudes uma delas é: Se o CPF da pessoa que está realizando a transação existir dentro de uma coleção de CPFs classificados como fraudulentos, essa transação deve ser negada.
Uma implementação simples para essa regra de negócio seria gravar todos esses CPFs em uma tabela de um banco de dados relacional e, para cada transação que chegar, realizar um select simples nesta tabela para verificar se esse CPF existe. Caso exista, basta bloquear a transação.
Esta é uma solução válida e bem simples de implementar, porém a sua instituição bancária recebe centenas de milhares de transações diariamente e a base de dados de CPFs fraudulentos contém milhões de dados. Portanto, essa solução irá enfrentar um gargalo de performance muito grande por conta do tempo de acesso às informações.
Como foi explicado no primeiro post, acessar informações em disco é uma forma barata, porém lenta.
Para ajustar o problema de performance podemos implementar uma solução que talvez seja a mais utilizada nas aplicações que existem hoje no mercado.
Podemos em vez de acessar os CPFs em um banco de dados, carregar essas informações na memória utilizando uma estrutura de dados que ofereça a melhor performance possível para uma busca de uma chave única como o CPF, logo podemos utilizar o SET ou MAP.
Com essa solução temos uma ótima performance, pois o acesso a um dado que está em um SET é da ordem de O(1), ou seja, o acesso é instantâneo.
Impactos da solução com SET ou MAP
Agora temos uma solução performática e de baixa complexidade, afinal, o acesso a um elemento no SET é muito simples. Mas qual seria o principal problema dessa abordagem?
O primeiro problema a ser notado é o uso excessivo de memória, principalmente se a base de CPFs continuar crescendo de forma rápida. O segundo problema que pode passar despercebido é o tempo de startup da aplicação, ou seja, o tempo que demora para subir todas as informações dentro da coleção em memória.
Hoje com a ascensão da computação em nuvem toda aplicação paga pela quantidade de recursos que utiliza e cada byte a mais é cobrado. Além disso, cada byte utilizado é multiplicado pela quantidade de instâncias que a sua aplicação roda e o mesmo se aplica ao processamento.
Outro ponto é que a lentidão na inicialização da aplicação pode trazer várias dores de cabeças em aplicações que escalam dinamicamente. Mas como o bloom filter pode ajudar?
Proposta de Solução com o Bloom Filter
Uma solução que pode ser proposta para o problema apresentado é utilizar o bloom filter. Ele funcionaria como um tipo de cache que previne a aplicação de acessar o banco de dados em todos os momentos. Com isso o banco só será acessado quando necessário, ou seja, quando existir a possibilidade do CPF ser fraudulento.
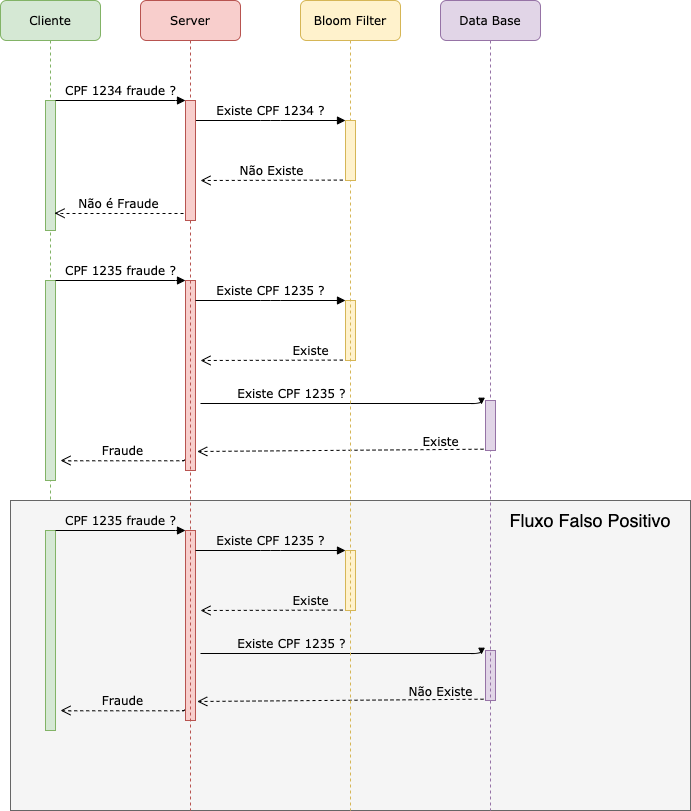
Essa abordagem tem a mesma eficácia que as apresentadas anteriormente. Porém, tem a vantagem de consumir menos memória por conta das características do bloom filter. Além disso, a inicialização do serviço só irá depender de incluir os dados no bloom filter e essa é uma tarefa muito rápida que pode trazer ganhos no start da aplicação.
Caso seja necessário ainda mais performance, pode-se utilizar um banco de dados em memória como fonte de dados, como o Redis, por exemplo. Assim a latência será ainda menor.
Lembrando que, caso algum CPF seja retirado da nossa base de dados será necessário gerar o bloom filter novamente para evitar falsos positivos e acessos desnecessários a base de dados.
Utilizar o bloom filter explorando a sua característica de nunca retornar um falso negativo pode ser uma abordagem muito útil no dia a dia de muitos engenheiros de softwares que trabalham com bases de dados muito grandes.
Conhecer o bloom filter e estudar as potenciais soluções que ele pode trazer pode ser um ótimo diferencial para você!
Nos próximos posts iremos abordar sobre outros tipos de estrutura de dados probabilísticas. Por isso, se inscreva na Newsletter da ZUP agora mesmo e não perca nenhum post!
Bibliografia
Brave New Geek – Stream Processing and Probabilistic Methods: Data at Scale




