

Enquanto a Engenharia de Software atua nos sistemas de software, o Deep Learning se volta em como extrair informações de forma automática desses sistemas. Neste artigo, vamos explicar a relação desses dois conceitos e em como Deep Learning pode ajudar nessa história.
Vamos descobrir lado a lado? Venha com a gente!
Engenharia de Software
A Engenharia de Software (Software Engineering – SE) investiga questões relacionadas a sistemas de software, como design, desenvolvimento, manutenção, teste e avaliação.
Com o avanço da tecnologia, os softwares estão cada vez mais importantes para o mundo e também mais complexos, o que torna ainda mais importante o uso do Aprendizado de Máquina (Machine Learning – ML) para ajudar no progresso dos métodos e técnicas utilizados em Software Engineering.
Durante muitos anos, o uso de Machine Learning exigia um processo longo e cuidadoso de engenharia de dados, além de uma expertise considerável no domínio do problema para transformar dados brutos em informações com as quais os modelos computacionais pudessem trabalhar.
Por exemplo, para identificar um bug em um código, a ML tradicional precisa que você extraia informações do sistema de software em análise, como trechos de código relevantes, frequência de comandos (por exemplo, quantidade de ifs), informações do sistema, caminhos de execução, entre muitos outros (podendo chegar a centenas de atributos!).
Deep Learning: abrindo as portas para o outro nível
Deep Learning (DL), por outro lado, é capaz de extrair essas informações de forma automática, dando sentido aos dados a partir da sua própria experiência ao processá-los (não se preocupe, vamos conhecer um pouco mais sobre DL logo a seguir ?).
Logicamente, com grandes poderes vem grandes necessidades, sendo fundamental fornecer mais poder computacional e mais dados para que Deep Learning possa aprender.
Por sorte nossa, a tecnologia avança atualmente para nos fornecer essa exata receita e, previsivelmente, esse maior poder computacional geralmente leva a melhores resultados.
Diversas áreas de pesquisa mudaram completamente com a chegada dos métodos de DL (e agora são dominadas por eles), por exemplo:
- Visão computacional, com grandes mudanças de fala, movimento, voz, etc. (o que é hoje conhecido como deepfake e que pode ser, sim, usado para o bem);
- Tradução de textos, tendo exemplos muito famosos e muito utilizados, como o Google Tradutor. Atualmente, mesmo línguas mortas podem ser traduzidas;
- Jogos de estratégia, como xadrez e GO, e até jogos mais complicados, como jogos multiplayer on-line, tipo DOTA2.
Naturalmente, essa incrível capacidade chamou a atenção da Pesquisa e da Indústria de Engenharia de Software, que passaram a estudar essa nova tecnologia para aplicar nos problemas da área.
Mas como Deep Learning funciona?
Deep Learning é a filha famosa da Computação Natural. Nessa área, todos os algoritmos querem resolver problemas complexos utilizando a natureza como inspiração. Porém, antes de entender DL, é importante conhecer Redes Neurais Artificiais (Artificial Neural Network – ANN).
De Redes Neurais Artificiais a Deep Learning
A inspiração biológica desse tipo de algoritmo é o cérebro. Sabe-se que nosso cérebro é composto basicamente de neurônios, conectados entre si através de uma região chamada sinapse. Pela sinapse, um neurônio transmite um impulso nervoso a outros neurônios quando são estimulados.
Neurologistas descobriram que o cérebro aprende mudando a resistência da ligação sináptica entre os neurônios sob repetida estimulação pelo mesmo impulso. Além disso, o cérebro está organizado em diversas camadas e possui um massivo paralelismo, além de alta distribuição na entrega de suas mensagens.
São essas ligações que, entre outras coisas, tornam o ser humano extremamente eficaz no reconhecimento de padrões e generalizações. Na tentativa de simular essa impressionante capacidade do sistema neural biológico, nasceu as redes neurais artificiais. De fato, as redes neurais são um cérebro metafórico, compostas de camadas paralelas formadas por nós (chamados de neurônios) que se interligam entre si (da camada anterior para a camada posterior), como vemos na imagem a seguir:
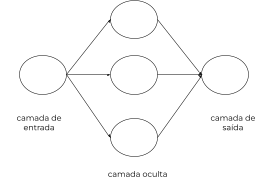
Matematicamente falando, o objetivo da rede neural é encontrar uma função que melhor represente o problema estudado, aprendendo os valores dessa função através da interação entre os neurônios (ou seja, mudando o valor das sinapses).
Há um teorema, chamado Teorema da Aproximação Universal, que afirma que uma rede neural com uma única camada oculta pode aproximar qualquer função contínua ao adicionar mais nós na camada oculta. Isto é, quanto mais neurônios na camada oculta, melhor fica a aproximação da função que representa o problema.
Claramente, adicionar um número enorme de nós na camada oculta não vai ser legal, levando a diversos problemas que impedem o uso desse tipo de algoritmo em problemas mais complicados.
Foi com essa motivação que surgiu o Deep Learning: paralelizar o aprendizado da camada oculta que pode aproximar qualquer função em várias camadas menores.
Então, DL é somente uma rede neural com anabolizantes? Não!
Muitas inovações surgiram a partir desse ponto, o que tornou Deep Learning esse transformador radical no nosso uso das tecnologias, mas isso é assunto para um outro papo.
Deep Learning em Engenharia de Software
Embora o uso de DL tenha começado a disparar por volta de 2012, graças ao modelo profundo mais famoso, a AlexNet (o artigo científico que explica esse modelo tem mais de 118 mil citações no Google Scholar!), a exploração em problemas relacionados a Engenharia de Software só deslanchou por volta de 2015.
Essa demora pode ter ocorrido devido a dificuldade de aplicação: as primeiras aplicações de Deep Learning eram voltadas para processamento de imagem e reconhecimento de fala, por exemplo, tipos de dados não tão comuns em SE. Assim, era necessário um esforço maior para transformar os problemas da área em dados com os quais os métodos DL pudessem trabalhar.
Porém, o mundo gira e a tecnologia avança. Com isso, se tornou muito mais fácil aplicar soluções baseadas em Deep Learning, independente do nível de habilidade, devido ao barateamento do poder computacional (como GPUs e memórias de baixo custo), os serviços de computação em nuvem mais acessíveis e a popularização de frameworks voltados para o desenvolvimento simplificado em DL (como PyTorch e Tensorflow).
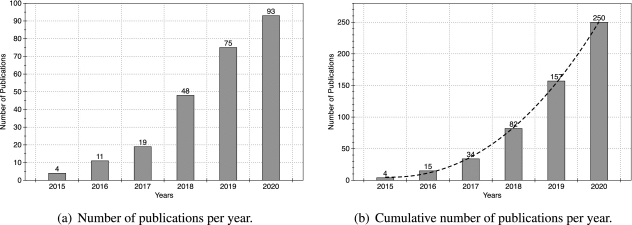
Isso não só ajuda a desenvolver as investigações desejadas, como também ajuda a fazer isso mais rápido. A Engenharia de Software seguramente desfruta dessas facilidades, o que aumenta o interesse na aplicação de DL a cada ano, como descrito no gráfico abaixo:
Quais atividades de Engenharia de Software são facilitadas pelo uso de Deep Learning?
Engenharia de Software é um solo fértil para o uso de Deep Learning, pois a quantidade de dados disponíveis é muito grande (por exemplo, há mais de 41 milhões de projetos públicos no GitHub).
Não só o código desses repositórios pode ser utilizado como fonte para o aprendizado das redes neurais profundas, mas também a documentação, os comentários, os testes, as issues, as interfaces gráficas, pull requests… Basicamente qualquer dado relacionado às atividades da Engenharia de Software.
Vamos conhecer um pouco mais como explorar problemas de Engenharia de Software com Deep Learning?
Requisitos de Software
Análise de requisitos
Para testar, manter, desenvolver ou até mesmo utilizar um sistema, é necessário entender suas funcionalidades, o que geralmente acontece através da documentação.
Existem diversas maneiras de descrever uma funcionalidade (algumas boas, outras nem tanto), e essa informação pode estar bem escondida dentro de uma documentação extensa, tornando a tarefa de entender o sistema bem trabalhosa.
Assim, a ideia aqui é utilizar os métodos de Deep Learning para extrair todas as possíveis funcionalidades e estados de um sistema através da documentação dos requisitos, diminuindo o trabalho manual das pessoas que precisam dessa informação.
Validação de requisitos
É necessário verificar se as funcionalidades implementadas realmente estão de acordo com os requisitos e se os requisitos estão de acordo com os padrões de qualidade desejados. Assim, as técnicas de DL podem ser utilizadas para identificar e determinar formas de validação da implementação dos requisitos no sistema.
Design de Software
Detecção de padrões de design de software
Esses são os famosos padrões de design de código (design patterns), que são soluções exaustivamente testadas para resolver problemas recorrentes de desenvolvimento.
Uma dificuldade na identificação desses padrões é que são vários, que podem ser utilizados de diversas maneiras dentro de um sistema, com diversas variações de implementação.
A ideia aqui então é detectar as utilizações desses padrões, a fim de ajudar no reuso e documentação dos sistemas de software, garantindo uma boa manutenção e ajudando na criação de testes. De forma semelhante, é possível também identificar code smells.
Criação de modelos de interface gráfica
Para criar uma interface gráfica, pode-se procurar um tutorial que construa uma interface parecida e seguir os passos. Muito tempo é gasto nessa atividade, naturalmente, pois é necessário achar uma interface gráfica que se goste, seguir o tutorial, etc.
Com Deep Learning, é possível mostrar ao algoritmo a interface desejada e a técnica irá te fornecer um esqueleto (uma composição de componentes) para que se construa uma interface semelhante.
Implementação de Software
Sugestão de código
Esse é o uso mais famoso atualmente, graças ao GitHub Copilot. A intenção nessa linha de pesquisa é utilizar modelos de DL para sugerir o código a ser implementado.
Essa sugestão de código pode ser a partir de, por exemplo:
- comentários no código, antes de implementar, escreva um código dizendo o que deseja e a mágica acontece;
- durante a implementação, semelhante a ideia do autocompletar textos;
- como queries (onde você busca numa base de dados enorme o código que implementa o que deseja).
Tudo isso em tempo real. As vantagens nesse caso são inúmeras; por exemplo, na ajuda do desenvolvimento de software por parte de pessoas programadoras com deficiência.
Geração de comentários/commits
A documentação de um sistema muitas vezes é negligenciada, o que torna difícil atividades como manutenção e teste. Uma forma encontrada de superar essas dificuldades é a utilização de métodos de Deep Learning para gerar comentários e commits descritivos do código.
Grau de relacionamento entre unidades de conhecimento no Stack Overflow
Stack Overflow é um fórum para pessoas compartilharem conhecimentos relacionados ao desenvolvimento de software. Nele, uma pessoa pergunta uma dúvida que tenha e outras pessoas podem interagir com essa dúvida através de uma thread (respondendo ou tirando mais dúvidas). A thread formada é chamada de unidade de conhecimento.
Assim, a ideia dessa aplicação é relacionar as unidades de conhecimento do Stack Overflow entre si e entre tópicos já existentes (mesmo escritas em linguagens diferentes), para que todo o conhecimento do fórum fique bem organizado, ajudando mais pessoas.
Teste de Software
Predição e detecção de defeitos e bugs
Utiliza-se Deep Learning para automaticamente extrair atributos de um sistema de software para que se possa prever ou detectar um defeito ou bug.
Os defeitos detectados podem ser dentro de um arquivo ou entre arquivos do sistema. Os atributos, por sua vez, podem ser retirados do código ou de mensagens de commit, comparando as mudanças do sistema e informando se aquelas mudanças geram um defeito ou bug.
Outra forma de localizar um bug com as técnicas de DL é aprender a relação entre os termos do relatório do bug e o estado do código, então, se o sistema encontrar outro estado semelhante, a pessoa usuária é avisada, podendo até sugerir formas de corrigir esses erros.
Geração de casos de teste
O objetivo dessa área é diferente de detectar os bugs, é automaticamente escrever casos de teste que possam ser utilizados pelas pessoas desenvolvedoras.
Isso pode identificar os bugs, mas é ainda mais poderoso, pois pode desenvolver suítes de teste inteiras para que as pessoas que desenvolvem, mantêm e testam software não precisem se preocupar com o lado mais mecânico dessa atividade, concentrando os esforços humanos em atividades mais complexas de teste.
Com isso, pode-se garantir um software de maior qualidade, pois tal software pode ser extensivamente testado.
Análise de programas
Essa análise se refere a qualquer tipo de investigação que possa ser realizada sobre a execução do software. Por exemplo, a predição de hot path, que deseja predizer o caminho que será mais utilizado durante a execução de software (o que pode ajudar no balanceamento de carga).
Outra aplicação é a inferência de tipos de linguagens semelhantes a JavaScript, ou seja, a depender do contexto de utilização, inferir qual o melhor tipo para o elemento do código. Isso pode ajudar na estabilidade e escalabilidade dos sistemas de software, ou seja, torna-se mais fácil manter e utilizar o sistema.
Outras técnicas de teste
As técnicas tradicionais de teste não foram pensadas para todos os avanços da tecnologia. Por exemplo, é muito complicado escrever testes para interfaces gráficas, jogos e sistemas autônomos (como carros). Sabendo disso, as pessoas estão cada vez mais utilizando o Deep Learning para que se possa conduzir testes mais apropriados para cada tipo de sistema.
Manutenção de Software
Detecção de clones
Copiar pedaços de códigos é uma maneira simples de reuso, mas que pode dificultar a manutenção, especialmente em casos de duplicação onde o código é escrito diferente, mas as cópias fazem tarefas semelhantes.
É para esses casos mais complicados que DL é aplicado, onde o algoritmo realiza uma conexão entre padrões léxicos e sintáticos dos códigos.
Reparo de programas
É uma ideia complementar a identificação de defeitos e bugs, onde além de localizá-los, corrige-se o sistema de forma automática, garantindo a utilização do sistema sem erros. Também é possível aplicar os métodos de Deep Learning para corrigir partes do código, como mudar o nome de funções inconsistentes com o resto do sistema.
Classificação de códigos
É uma atividade para automaticamente organizar softwares em grupos que possam descrever o comportamento. É semelhante a organizar uma AppStore de forma automática, assim, ao buscar por jogos, é possível encontrá-los, sem que pessoas tenham feito essa organização prévia.
Outra aplicação nesse sentido é a identificação do mesmo algoritmo em diferentes linguagens.
Revisão de códigos e avaliação da qualidade do código
Um código sem erros aparentes não necessariamente é um código bem escrito, pois é necessário considerar diversas questões, como se é um código seguro, se segue boas práticas, se é fácil de ler, entre outros.
Isso é especialmente interessante para pessoas que estão aprendendo a desenvolver. Aqui na Zup temos uma experiência interessante com o processo de code review na nossa área de educação.
Gerenciamento de Software
Estimação do esforço de implementação
Segundo estudos sobre entregas, apenas 40% dos projetos de software são entregues no tempo; 44% são entregues dentro do orçamento e 56% são entregues possuindo um bom número de funcionalidades.
É necessário então estimar o custo do desenvolvimento de forma mais precisa, para que o time possa se programar e entregar o valor desejado.
Criação de base de dados com rótulos
Diversas atividades descritas anteriormente dependem de dados com rótulos para serem executadas. Por exemplo, para identificar bugs, é necessário ter uma base de dados onde esteja rotulado qual parte do código gera um bug. Porém, nem sempre é fácil obter esse tipo de informação.
É possível sim criar essa rotulação manualmente, mas é um trabalho muito custoso e entediante. Felizmente, com Deep Learning podemos aumentar a quantidade de rótulos de uma base de dados, ou até mesmo gerar mais exemplos artificiais que sejam muito parecidos com um exemplo real, o que pode aumentar a confiança dos resultados obtidos pelos algoritmos ao aprender da base de dados.
Isso é bem importante especialmente em aplicações mais sensíveis, como em sistemas médicos.
Conclusão
Vimos que há diversas possibilidades para o uso de Deep Learning em Engenharia de Software e com certeza há sempre mais a ser descoberto.
Esperamos que esse artigo possa te ajudar a entender melhor como enriquecer ainda mais a pesquisa na área de Software Engineering. Mais ainda, quem sabe esse artigo possa te dar ideias de como aplicar DL em problemas que você enfrenta atualmente?
Ficou com alguma dúvida? Tem alguma sugestão? Quer discutir um pouco sobre o assunto? Só entrar em contato pelo Linkedin ou enviar seu comentário abaixo.
Referências
YANG, Yanming et al. A survey on deep learning for software engineering. ACM Computing Surveys (CSUR), v. 54, n. 10s, p. 1-73, 2022.
WATSON, Cody et al. A Systematic Literature Review on the Use of Deep Learning in Software Engineering Research. ACM Transactions on Software Engineering and Methodology (TOSEM), v. 31, n. 2, p. 1-58, 2022.
LI, Xiaochen et al. Deep learning in software engineering. arXiv preprint arXiv:1805.04825, 2018.
WANG, Simin et al. Synergy between machine/deep learning and software engineering: How far are we?. arXiv preprint arXiv:2008.05515, 2020.



