

Entre uma sprint e outra, algumas vezes já me deparei com o seguinte desejo: Seria muito bom se minha IDE fizesse code review e avaliasse a qualidade do código de forma automática! Não estou falando somente de avaliar se o código compila ou não, mas será que uma Inteligência Artificial (IA) poderia avaliar se o código está bem escrito? Se está performático? É seguro? É acessível?
Se uma IA pudesse dar uma nota para ele, qual seria? Será que a minha IDE conseguiria avaliar, mensurar e sugerir melhorias de implementação para o meu código? ?
Por mais que existam plug-ins e ferramentas que tentem entregar algo parecido, ou próximo a isto (como é o caso do SonarQube) muitas destas focam em análises estáticas de código e ainda possuem lacunas quanto a precisão destas análises, principalmente em aspectos de mensuração de códigos, como podemos observar em algumas pesquisas, como as realizadas por Reynolds, Nunes, Landman e Lavazza.
Ok, mas frente às várias dimensões possíveis de se analisar um projeto de software, afinal, o que é um bom código? Como avaliar se um código realmente é o ideal? O que deve ser analisado? Enfim… isso já são tópicos para um próximo artigo aqui no blog. Mas antes de falarmos sobre isso, vamos focar em como estruturamos algo que torne estas análises possíveis de serem realizadas por um computador!
Neste artigo vamos conversar um pouco sobre estratégias de como modelos de inteligência artificial podem ser utilizados para interpretar códigos-fonte desenvolvidos pelo time, possibilitando a geração de code reviews e mensurações automáticas para apoio à tomada de decisão.
Esta publicação é resultado de estudos realizados pelo time de pesquisa da Zup.Edu, que visa ao incentivo e investigação da cultura do preparo, buscando fornecer as ferramentas necessárias para o crescimento exponencial dos times.
Processamento de Linguagem Natural: Fazendo um computador entender o que você escreve
Antes de começarmos a falar sobre como um modelo de inteligência artificial entende um código, é importante conversarmos sobre como um computador entende um texto, ainda mais quando este texto não está estruturado (não obedecendo a uma organização ou padrão predefinido).
Os algoritmos, no geral, trabalham muito bem com dados estruturados, como planilhas, arquivos csv, xml e tabelas de um banco de dados, mas os seres humanos se comunicam de forma não estruturada, nós utilizamos gírias, sarcasmo e possuímos diferentes sotaques.
Por exemplo, dependendo da conotação, uma frase como “Esse cara é um monstro” pode ter mais de um sentido. Embora isso possa ser bem interpretado por nós, humanos, isso é terrível para uma interpretação automática de uma máquina.
Sabendo que a maior parte dos dados do mundo são não estruturados, como fazer com que um algoritmo entenda um texto não estruturado e consiga extrair informações relevantes dele? Para isso vamos precisar de Processamento de Linguagem Natural (PLN)!
Mas o que é Processamento de Linguagem Natural (PLN)?
O Processamento de Linguagem Natural (PLN) é um subcampo da inteligência artificial que se concentra em permitir que os algoritmos entendam e processem a linguagem humana. Em certas áreas, estes algoritmos podem parecer até mágica.
O PLN pode ser utilizado na criação de sistemas especialistas para o reconhecimento de voz, análises de sentimentos em textos, resumos de documentos, traduções automáticas, detecção de spams, respostas automáticas a perguntas, dentre outras áreas.
Algumas soluções como a Alexa, a Siri e o Google Assistant são exemplos de uso do PLN na prática.
Mas nem tudo são flores.
Extrair significado e informações relevantes de textos ainda é uma atividade complexa. Pois bem, como é comum quando queremos lidar com atividades complexas em aprendizagem de máquina, vamos ter que construir pipelines para lidar com essas situações; a clássica abordagem do dividir para conquistar.
Pipeline típica de Processamento de Linguagem Natural
Você pode estruturar sua pipeline de execução de diferentes formas a depender do tipo de problemática que está lidando, mas a nível de exemplo, vou descrever aqui uma pipeline típica de PLN.
Vamos partir do pressuposto que eu tenho um texto de blog, parecido com este, e quero o analisar para extrair algo de forma automatizada. Como consigo fazer isso de uma forma simples? Vamos por partes.
- Etapa 1 – Segmentação de sentença: Aqui você vai quebrar o texto em frases separadas;
- Etapa 2 – Tokenização de palavras: Agora que dividimos nosso texto em frases, podemos processar cada palavra de uma vez;
- Etapa 3 – Sintaxe de cada token: A seguir, podemos examinar a classe gramatical de cada token, se é um substantivo, um verbo, um adjetivo e assim por diante. Saber o papel de cada palavra na frase nos ajudará a começar a descobrir do que a frase está falando;
- Etapa 4 – Lematização do Texto: As palavras normalmente têm variações. Um verbo, por exemplo, pode estar no infinitivo, no gerúndio, em um tempo passado. Essa técnica nos ajuda a padronizar as variações das palavras;
- Etapa 5 – Identificação e remoção de stop words: Artigos e preposições, são exemplos de stop words, palavras que aparecem muitas vezes no texto e não necessariamente têm uma importância grande para a identificação do seu significado;
- Etapa 6 – Análise de dependência: A próxima etapa é descobrir como todas as palavras em nossa frase se relacionam entre si. Aqui podemos verificar sujeitos e objetos, por exemplo, e analisar as dependências entre os tokens da sentença;
- Etapa 7 – Análises e Reconhecimento de Token: Quando chegamos neste ponto já temos uma representação útil de nossa frase. Já conhecemos suas classes gramaticais e como as suas palavras se relacionam. Nesta fase, você pode aplicar diferentes técnicas de análise, um exemplo é o reconhecimento de entidade nomeada (NER), onde as palavras são analisadas para serem classificadas como lugares, pessoas, empresas e datas, por exemplo. Outra técnica que pode ser utilizada é a de resolução de correferências, que permite buscar relações entre termos de frases diferentes.
Com estas 7 etapas conseguimos através do Processamento de Linguagem Natural fazer com que uma máquina consiga analisar um texto de blog e extrair, de forma automatizada, informações que podem ser relevantes para uma análise.
Certo, a esta altura do campeonato acredito que você já entendeu o que é o processamento de linguagem natural, mas você pode estar se perguntando: Mas linguagens de programação não são linguagens naturais, são linguagens formais!
Além do mais, um computador já sabe interpretar e executar isto. Então, por que isso ainda seria uma atividade complexa? Calma… vamos falar mais sobre isto a seguir.
Mas por que fazer um modelo de inteligência artificial entender um código é algo importante?
Como dei spoiler antes, linguagens de programação seguem um padrão de escrita formal, o que possibilita que algum interpretador ou compilador consiga “entender” o algoritmo e o executar da forma correta, logo possibilitando que o computador consiga entender este código escrito, já que ele segue um formalismo.
Porém, esse formalismo normalmente limita a possibilidade de você implementar um código e fazer com que ele seja executado. Contudo, para um problema em específico eu posso ter uma série de variações possíveis de implementações que podem retornar o mesmo resultado. E aqui é que se inicia a complexidade. Como eu consigo determinar quais, dentre estas variações possíveis de implementação, seria a ideal?
Há análises em que os compiladores e IDEs não necessariamente estão prontos para fazerem, por exemplo, fatores como performance, segurança, acessibilidade, legibilidade, boas práticas etc. Desta forma, precisamos de outras abordagens para a análise destes códigos, os code reviews.
Para estes tipos de análises, o código-fonte assume um papel mais próximo de uma linguagem natural, pois ele se comporta como um dado não estruturado. Nestes cenários, irá depender, normalmente, de alguma ferramenta terceira, plugin ou modelo de inteligência artificial, que consiga interpretá-lo e extrair informações relevantes, atuando diretamente no processo de code review.
Code review e ferramentas de revisão automática de código
Em um ciclo de vida de desenvolvimento de software, sistemas de code review desempenham um papel crucial para a qualidade final do código. Entregas de projetos de software, dentre outros fatores, devem ser confiáveis e livres de ameaça, porém, a realização de revisões de código de forma manual é uma prática sujeita a muitas falhas, além de ser um processo demorado e trabalhoso.
Para superar esta situação e entregar códigos de alta qualidade, a comunidade busca a utilização de ferramentas para a revisão automática de código, através de inspeções contínuas de qualidade e análises estáticas. Atualmente existem algumas opções no mercado de ferramentas de code review, por exemplo:
- Checkstyle.
- FindBugs.
- PMD.
- NewRelic.
- Codacy.
- Code Climate.
- SonarQube (já comentado no início do artigo).
Todas as ferramentas anteriormente citadas são embasadas em técnicas de análises estáticas de código, que podem ser descritas como um método de depuração que examina automaticamente o código antes de um programa ser executado.
Esta ação é possível graças a um processo de análise de um conjunto de códigos em relação a um conjunto de regras de codificação (que documentam boas práticas para uma linguagem específica).
Estas ferramentas fazem testes de caixa branca por meio dos quais inspecionam o código antes de ser executado ou compilado. Eles fazem isso para descobrir erros durante o desenvolvimento. Os erros identificados podem ser erros de sintaxe, de estilo, vulnerabilidades de segurança ou erros de codificação que não atendem aos padrões.
Para que esses analisadores sejam eficazes, eles devem ter um entendimento claro da estrutura, regras e componentes internos do projeto em que estão trabalhando.
Alguns benefícios do uso destas ferramentas:
- Garantir maior qualidade do código;
- Descoberta de insights de vulnerabilidades em dependências;
- Detecção de erros de sintaxe;
- Velocidade de revisão de código, em comparação com a manual;
- Análise detalhada que pode ajudar a fase de testes;
- Menos sujeito a erros, em comparação com as revisões manuais.
Lacunas nas ferramentas de revisão automática de código
Embora estas ferramentas ofereçam uma série de benefícios aparentes, elas não são as melhores determinantes da confiabilidade de uma aplicação. As rotinas de testes ainda apresentam resultados mais eficazes.
Estas ferramentas precisam ter um entendimento completo do funcionamento interno da aplicação, os códigos passam por um analisador que verifica linha a linha apontando erros com base em vários conjuntos de regras que foram especificados, um exemplo disso é o ESLint.
Mas e se existirem erros não documentados nestas regras? E quanto a análises mais subjetivas, como a avaliação ou mensuração de um mentor e/ou professor quanto a um código, ou projeto? Estas análises mais subjetivas, ou não especificadas, normalmente não são contempladas por estas ferramentas.
Nossa investigação
Este artigo investiga técnicas que possibilitem interpretar um código além de sua execução e de análises estáticas básicas, para inclusive possibilitar uma mensuração futura de um código, algo como, este código-fonte é nota 8! E futuramente possibilitar modelos de avaliação e sugestão ainda mais sofisticados, que indiquem, por exemplo, o que falta para este código em específico ser nota 10.
Buscamos mecanismos que possam futuramente possibilitar a construção de Ambientes de Desenvolvimento Orientados por Inteligência artificial (AIDEs).
Então aqui estamos nós, investigando abordagens de como um modelo de inteligência artificial consegue interpretar códigos-fonte para futuramente conseguirmos desenvolver modelos ainda mais robustos para entenderem os códigos escritos pelas pessoas desenvolvedoras, conseguindo dar retornos mais precisos quanto a aspectos de mensuração, avaliação e recomendação.
Como o time de pesquisa da Zup.Edu estruturou essa investigação
Sempre procuramos orientar nossas pesquisas e investigações ao método científico, procurando respaldar nossas hipóteses e achados a metodologias já bem estruturadas e reconhecidas pela comunidade científica.
Realizamos um levantamento superficial do estado da arte e da técnica tomando como referência a seguinte pergunta de pesquisa: “Como Transformar um Código-fonte em Algo Compreensível para um Modelo de Inteligência Artificial?”.
Durante nosso processo de busca ainda utilizamos algumas palavras chaves como filtro de escolha dos artigos e ferramentas, foram elas: code review, code smells, code defect, code prediction, continuous quality inspections, static analysis, textual representation e feature extraction.
Sempre em busca de artigos de relevância e ferramentas que combinassem essas palavras chaves com termos como: machine learning; deep learning e artificial intelligence.
Com o término deste processo, separamos 48 artigos e 7 ferramentas (que já foram citadas aqui no post). Com isso, esperamos ter encontrado um baseline teórico para fundamentar algumas decisões de pesquisa que vamos tomar para futuros experimentos e simulações.
Durante a revisão dos artigos, demos preferência às pesquisas de revisões e surveys, pois estes tipos de publicações já consolidam análises de um conjunto de outras pesquisas, apontando abordagens, técnicas, metodologias, lacunas e oportunidades no estado da arte daquilo que foi investigado.
Por fim, os resultados e achados desta pesquisa foram discutidos entre o time de pesquisa da Zup.Edu, para validação dos métodos e técnicas utilizados. Em seguida, foram apresentados e discutidos por todo o time da Zup.Edu e agora estamos divulgando aqui no blog para conhecimento da comunidade como um todo ?.
Então, finalmente vamos aos nossos achados e as principais respostas sobre como conseguimos fazer com que um modelo de inteligência artificial consiga interpretar códigos-fontes para futuros code reviews.
Abordagem 1: Espaço vetorial e conversão de códigos em representações numéricas

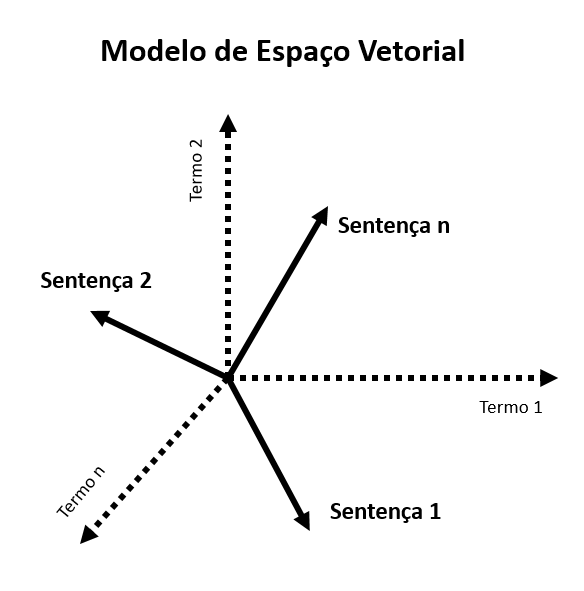
Para a nossa problemática, os códigos-fonte podem ser interpretados como dados não estruturados. Isso logo de cara nos permite olhar para as principais técnicas utilizadas no processo de representação de textos naturais para modelos de inteligência artificial. Então vamos levar nossos códigos para o espaço… para o espaço vetorial!
Sem muito suspense, essa primeira abordagem é a mais utilizada pela literatura. Ela defende que para utilizarmos modelos clássicos de aprendizagem de máquina ou de deep learning no Processamento de Linguagem Natural, por vezes, vamos precisar de alguma estratégia de representação dos nossos códigos, ou seja, fazer uma conversão do código-fonte original em uma representação numérica, por exemplo.
Para realizar este processo de representação do nosso código vamos precisar extrair features, que podem ser entendidas como informações mensuráveis acerca de algum fenômeno, uma forma estruturada de armazenar e representar informações.
Esta tarefa é formalmente conhecida como uma atividade de feature extraction, focada em transformar nosso código em uma informação numérica que permita ser utilizada em um modelo de aprendizagem de máquina, mantendo suas características. Uma das maneiras mais populares e simples de fazer isso é com técnicas de Bag of Words (BOW) e TF-IDF.
Neste ponto, já conseguimos representar nosso código para o nosso modelo de inteligência artificial, possibilitando que ele consiga interpretar aquilo que foi escrito.
Representações discretas e Representações distribuídas/contínuas
Existem diferentes formas de como podemos gerar essas representações, podendo ser amplamente classificadas em duas seções, representações discretas ou Representações distribuídas/contínuas.
A representação distribuída é a mais utilizada quando precisamos que a representação de uma palavra não seja independente ou excludente de outra palavra. Portanto, temos a informação sobre uma determinada palavra distribuída ao longo do vetor como ela é representada.
Já a representação discreta é quando cada palavra é considerada única e independente uma da outra.
Alguns exemplos de técnicas:
Representações discretas:
- Codificação One-Hot;
- Representação de saco de palavras (Bag of Words, BOW);
- BOW básico – CountVectorizer;
- BOW avançado – TF-IDF.
Representações distribuídas / contínuas:
- Matriz de co-ocorrência;
- Word2Vec;
- GloVe.
Bag of Words vs word embedding
Técnicas baseadas no Bag of Words, como o one-hot vectors e o TF-IDF são métodos que possuem limitações, tanto por perderem parte do sentido semântico e sintático das palavras, como pela sua própria estrutura, onde os vetores gerados têm o mesmo tamanho do vocabulário, o que se torna um problema quando temos vocabulários muito grandes.
Por isso, para a nossa problemática, vamos precisar de técnicas baseadas em processos de word embedding, ou seja, representações vetoriais que consigam aprender características e diferentes dimensões relacionadas a cada token analisado.
No word embedding é gerado um mapa de valores multidimensionais para representar de forma algébrica as coordenadas espaciais dos nossos tokens nos códigos. Com isso, conseguimos utilizar a matemática a nosso favor, efetuando operações para determinar, por exemplo, a distância semântica entre os tokens de um texto, ou nosso caso, em um código.
Word2Vec
Uma das técnicas mais populares baseada em word embedding é a Word2Vec. Ela é uma combinação de modelos usados para representar representações distribuídas de palavras em um corpus (conjunto de textos ou documentos sobre um determinado tema). Em resumo, o Word2Vec é um algoritmo que aceita corpus de texto como entrada e produz uma representação vetorial para cada palavra, desta forma:
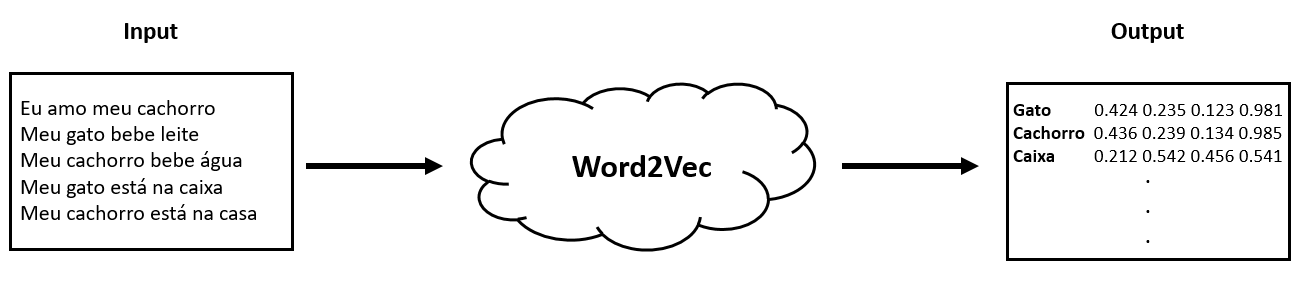
A grande sacada destas técnicas é possibilitar que sejam fornecidas muitas informações multidimensionais para o processo de treinamento dos modelos de inteligência artificial.
Por exemplo, um vetor de representação da palavra “gato” tende a estar próximo, em um espaço vetorial, de um vetor que representa a palavra “cachorro”, o que pode indicar uma relação de similaridade entre essas palavras.
A seguir, é ilustrado um exemplo de um fluxo de entrada de um corpus linguístico, neste caso, representado por um projeto de software, em um pipeline para geração de suas representações.
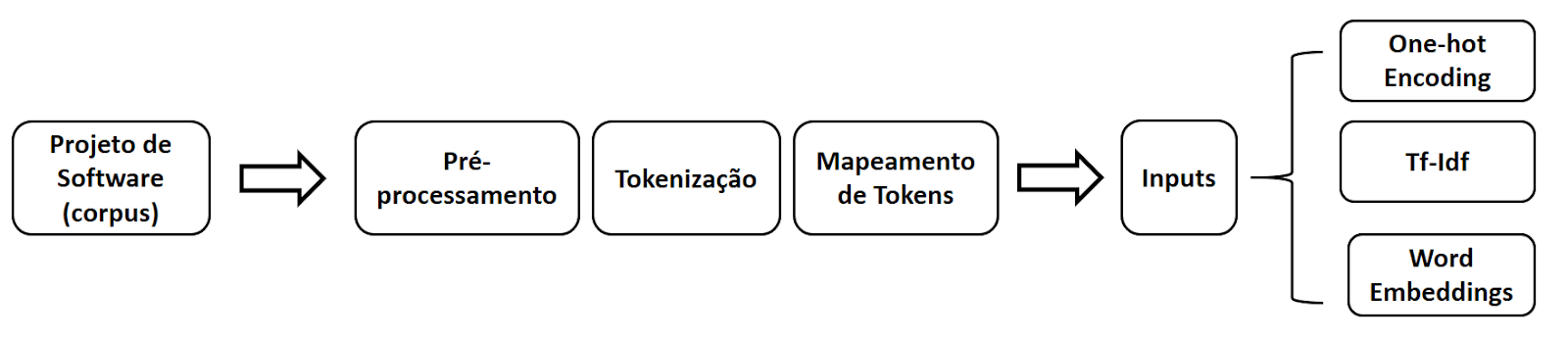
Outras técnicas para representações
O Word2Vec é só a porta de entrada para este mundo de geração de representações de códigos-fonte para serem analisados por modelos de inteligência artificial.
Apresentamos ele aqui, como exemplo, por ser o mais didático, mas em nossa pesquisa procuramos nos aprofundar nas principais técnicas que vêm sendo utilizadas na geração destas representações e quais estão apresentam os melhores resultados.
Dentre as principais técnicas utilizadas no processo de representação e code review para modelos de inteligência artificial, podemos destacar: AdaBoost, LSTM, GRU, RNN, Code2Vec, Random Forest, Doc2Vec, Gradient boosting, Decision Tree, Naive Bayes, SVM, Transformer e encoder decoder.
Também levantamos os principais datasets utilizados na área para treinamento destes modelos (entenda que estes datasets podem substituir os corpus em algumas análises): ncc, code2vec, code2seq, cc2vec, autoenCode, graph-based code modeling, vocabulary learning on code, user2code2vec e o ghtorrent.
Por fim, encontramos resultados significativos em novas técnicas de embeddings combinando o clássico sentence embeddings + cross entropy com o contrastive learning. As referências para essas técnicas mais atuais podem ser encontradas clicando aqui, aqui e aqui. Abordagens de representação de código com contrastive learning vêm apresentando ótimos resultados.
Abordagem 2: O básico é estruturar!

Apesar da estratégia de representação numérica/vetorial ser a mais popular na literatura, ela não é a única possível, nem uma bala de prata para todos os casos.
Vimos que o básico para conseguirmos começar a tomar decisões sobre um determinado conjunto de dados é criando algum processo que permita a sua estruturação. Pois bem, aqui vamos conversar sobre como estruturar um código-fonte para que seja possível a sua compreensão e análise por uma máquina.
Tags
A recomendação geral da W3C para marcações e estruturação de conteúdos e códigos na web é o uso de tags. Desta forma, podemos utilizar as tags como elementos básicos para a estruturação, classificação e extração de features de códigos por nossos modelos de inteligência artificial.
O conceito de “tag” quando expandido para contextos não necessariamente ligados ao da web pode ser compreendido como algo que indique o início e o fim de um bloco de código e que traga um conceito semântico para ele, além de sua própria funcionalidade em si.
Desta forma, podemos encontrar alguns elementos utilizados na literatura para este processo de estruturação, são eles:
- Tags;
- Annotations;
- Comentários;
- Chaves, Colchetes e parênteses;
- Indentação.
Outras formas de estruturar
Ainda encontramos pesquisas que utilizam estratégias de estruturação de código com tags XML buscando converter os elementos marcados em elementos RDF (Resource Description Framework). A ideia desta estruturação é enriquecer os conteúdos marcados para que possam ser compreendidos por um computador e que ainda possam ser utilizados em cases de web semântica.
Por fim, o importante aqui é conseguir criar, ou identificar, um padrão de estruturação nos códigos-fonte para que estes possam ser passados para modelos computacionais e estes consigam realizar análises e gerar insights quanto ao que foi escrito.
Abordagem 3: Sistemas especialistas

Antes do hype de pesquisas em Deep Learning, do grande interesse por esta tecnologia e pela área de inteligência artificial em si, as análises e pré-processamentos de código eram realizados de uma forma um pouco diferente… mesmo sendo considerada uma técnica ultrapassada por algumas pessoas, muitos feitos na área de análise e revisão de código foram obtidos utilizando abordagens de análises estáticas de código.
Logo, não precisamos necessariamente usar inteligência artificial para tudo! Sim, às vezes as ferramentas e técnicas básicas para a representação e análise estática de um código-fonte são o suficiente para atender as necessidades de uma pessoa desenvolvedora.
As técnicas baseadas nessas abordagens geram sistemas especialistas em analisar e determinar a existência, ou não, de uma determinada característica no código. Basicamente estes sistemas visam a listagem de uma série de características já predefinidas e estáticas que um algoritmo especialista executa verificando se essas características existem, ou não, no código. Com isso, é possível identificar más práticas e sugerir abordagens mais eficientes.
Um exemplo claro desta abordagem é quando estamos escrevendo um código e recebemos uma mensagem de “deprecated”. Não foi preciso necessariamente uma inteligência artificial para descobrir que aquele trecho de código estava descontinuado, sua IDE pode simplesmente ter uma lista de termos que sabe que são classificados como descontinuados e retornar esse alerta sempre que um deles é utilizado.
Onde e como podemos utilizar estas abordagens na Zup?
Como já vimos, possibilitar que um modelo de inteligência artificial consiga ler, interpretar e analisar um código, pode ser útil e resultar em uma série de aplicações relevantes no dia a dia de pessoas desenvolvedoras.
Na Zup.Edu temos interesse total nesta investigação. A possibilidade da existência de um modelo de inteligência artificial para análises amplas e complexas para apoio no dia a dia de zuppers é algo que nos incentiva muito.
Nosso foco inicial é concentrar esforços de pesquisa e desenvolvimento para a implementação de um modelo de inteligência artificial para a mensuração dos códigos desenvolvidos em nossos programas de formação e aceleração. Inicialmente buscamos um modelo que consiga de forma automática mensurar com uma nota de 0 a 10 a qualidade e assertividade de um código desenvolvido.
Futuramente o time de pesquisa da Zup.Edu tem total interesse em evoluir o modelo desenvolvido para que este possa suportar o fornecimento de outputs de avaliação e sugestão do código analisando, retornando de forma automática pontos de melhorias e possíveis dicas para as pessoas desenvolvedoras.
Para chegarmos nesse nível, estamos executando uma série de pesquisas e experimentos buscando o estado da arte e da técnica nas áreas correlacionadas ao estudo para termos um modelo robusto e que futuramente possa ser utilizado como apoio no processo de desenvolvimento de qualquer zupper.
Conclusões e o que vamos fazer daqui para frente
Existem vários desafios ainda abertos nesta área de pesquisa. Boa parte dos estudos encontrados focam em representações de texto para modelos de IA. Percebemos que pesquisas mais robustas utilizando estratégias de “code representation” começaram a surgir a partir de 2018 e apresentam uma problemática em comum, como otimizar as representações de códigos para modelos de IA mantendo as nuances e “semânticas” passadas pelas pessoas desenvolvedoras?
As áreas de pesquisa de code representation e code review devem se manter no nosso radar por um tempo e esperamos colaborar com a área avançado no estado da arte e gerando discussões conjuntas com a comunidade. O resultado positivo de pesquisas nestas linhas pode agregar muito valor ao dia a dia de pessoas desenvolvedoras, possibilitando a construção de softwares de qualidade elevada, com menor custo e tempo.
Se você gosta de pesquisa aplicada, te convidamos a ouvir esse papo no ZupCast sobre Pesquisa Acadêmica em Tecnologia.
Ficou com alguma dúvida? Tem alguma sugestão? Quer falar com a gente? Então é só enviar algo aqui nos comentários ou nos procurar no Linkedin.
Pretendemos manter a comunidade informada quanto ao avanço das nossas pesquisas e os nossos achados, então até a próxima ?!



